
综述九:LLM
提示(Prompts)
Large Lanuage Models Can Self-Improve in Long-context Reasoning (24/10)
论文地址
核心思想:大型语言模型(LLM)在处理长上下文方面取得了实质性进展,但在长上下文推理方面仍存在困难。现有的方法通常涉及使用合成数据对LLM进行微调,这取决于人类专家的注释或GPT-4等高级模型,从而限制了进一步的进步。为了解决这个问题,研究了LLM在长上下文推理中自我改进的潜力,并提出了专门为此目的设计的SEALONG方法。这种方法很简单:对每个问题的多个输出进行采样,用最小贝叶斯风险对其进行评分,然后根据这些输出进行监督微调或偏好优化。在几个领先的LLM上进行的广泛实验证明了SEALONG的有效性,Llama-3.1-8B-Instruct的绝对提高了4.2分。此外,与依赖于人类专家或高级模型生成的数据的先前方法相比,SEALONG实现了更优的性能。我们预计,这项工作将为长期情景下的自我提升技术开辟新的途径,这对LLM的持续发展至关重要。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Model The World!
相关推荐
2024-11-24
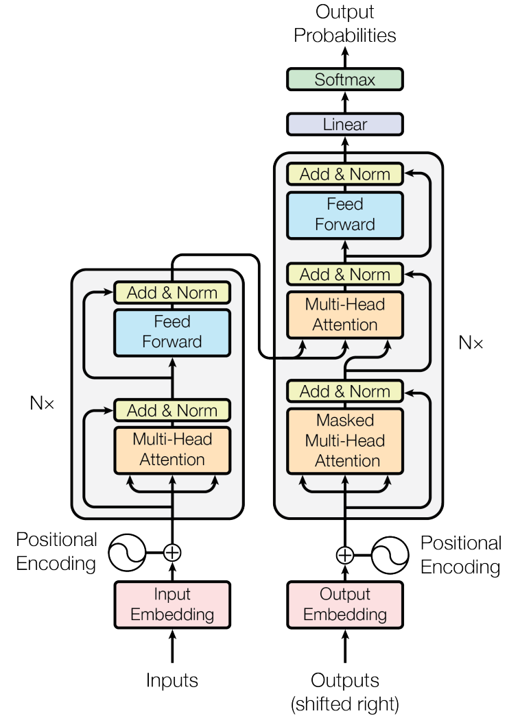
综述一:Transformer及其变体
Transformer架构,因其自注意力机制而闻名,能够让模型根据输入序列中不同的标记之间的关系进行加权。这种机制消除了循环神经网络的需求,使得训练变得更加高效。自从2017年原始Transformer的提出以来,已经出现了多个变种,旨在优化性能、扩展其适用范围或解决一些挑战。以下是一些著名的Transformer变种,特别是那些专注于自注意力机制的: 1. 原始Transformer (Vanilla Transformer) 关键特性:原始Transformer架构包括一个编码器-解码器结构,采用自注意力机制。 目的:消除了递归神经网络的需求,使得模型训练更加并行化和高效。 自注意力机制:多头自注意力,通过计算输入序列中所有标记之间的关系来决定重要性。 2. BERT(双向编码器表示) 关键特性:BERT只使用Transformer的编码器部分,采用双向自注意力机制来捕获标记的左右上下文。 目的:通过掩蔽语言模型(MLM)进行预训练,并可以通过微调来提升在下游NLP任务中的表现。 3....
2024-11-24
综述七:CNN模型
Here’s a list of major CNN (Convolutional Neural Network) variants ordered by the time of their publication. CNNs have evolved over the years to improve accuracy, reduce computational costs, and adapt to different domains. 1. LeNet (1998) Key Idea: One of the first CNN architectures, designed for handwritten digit recognition (MNIST). It used convolutional layers followed by pooling and fully connected layers. Application: Digit classification. Notable Paper: Yann LeCun et al.,...
2024-11-24
综述三:持续学习及其方法
持续学习(Continual Learning,CL),也称为终身学习(Lifelong Learning),指的是模型能够从持续不断的数据流中学习,并随着时间的推移不断适应和获得新知识,而不会遗忘先前学习的内容。持续学习面临的一个主要挑战是灾难性遗忘(Catastrophic Forgetting),即在学习新任务时,模型容易遗忘之前学习的任务。 为了应对这些挑战,提出了多种方法,这些方法可以根据它们如何处理遗忘、如何存储知识以及如何使用新数据进行分类。 下面是主要的持续学习方法,按它们所采用的主要策略进行组织: 1....
2024-11-24
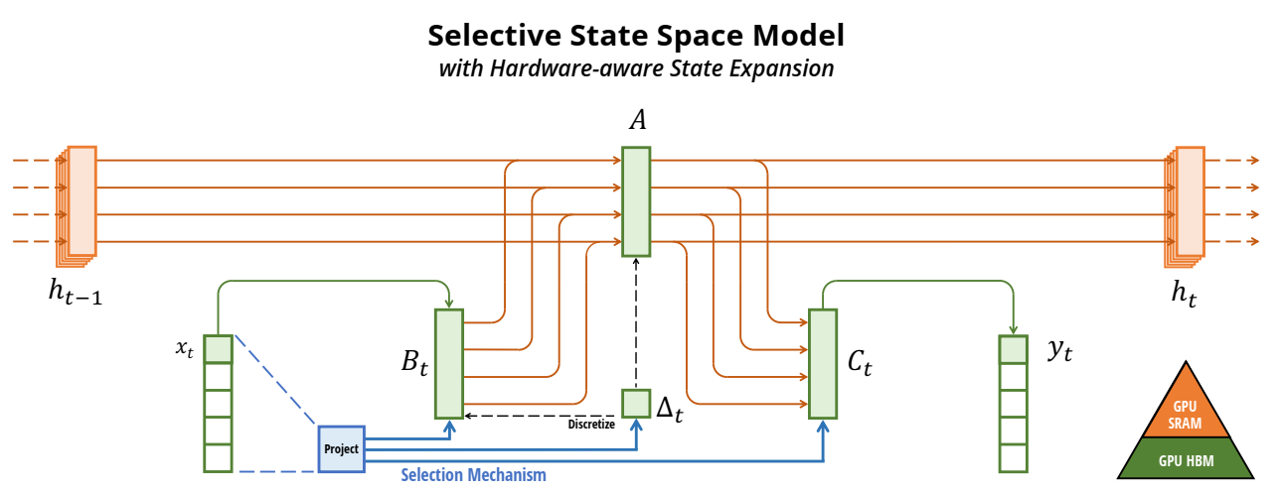
综述九:Mamba及其变体
SSM模型 Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (20/06) 论文地址 核心思想:将自注意表示为核特征图的线性点积,并使用矩阵乘法的结合属性将复杂度从 O(N2)\mathcal{O}(N^2)O(N2) 减少到 O(N)\mathcal{O}(N)O(N) ,其中N是序列长度。我们证明,这个公式允许迭代实现,大大加速了自回归Transformers,并揭示了它们与循环神经网络的关系。(一种涉及循环的自我注意近似,可以看作是退化的线性SSM) Hungry Hungry Hippos: Towards Language Modeling with State Space Models...

2024-11-24
综述二:DiTs及其变体
**DiT(去噪扩散Transformer模型)**是结合了Transformer架构和扩散模型的一类生成模型,特别专注于在扩散框架内的去噪过程。扩散模型通过逐步添加和去除噪声的过程来建模复杂的分布,近年来在生成任务中非常流行。 下面是一些著名的DiT变种,它们在不同方面扩展了原始的DiT模型: 1. DiT(原始版本) 关键特性:原始的DiT模型将Transformer架构与去噪扩散过程结合,利用Transformer的注意力机制改进生成质量和训练的可扩展性。 目的:生成高质量的图像,并与传统的卷积神经网络相比,提高训练效率。 2. DiT++(增强版DiT) 关键特性:DiT++是在原始DiT基础上进行增强的版本,可能包括模型架构的改进、训练方法的优化或额外的正则化技术。 目的:通过改进Transformer架构和扩散过程中的噪声调度,提升生成稳定性和性能。 3....
2024-11-24
综述五:强化学习及其分类
强化学习的变种 强化学习(Reinforcement Learning,简称RL)是一种机器学习方法,其中代理(Agent)通过与环境的交互来学习做出决策。代理的目标是通过采取适当的行动,最大化长期累积的奖励。强化学习是一个广泛的领域,许多不同的变种和算法已被开发出来,以解决学习、探索和决策等不同方面的问题。 以下是强化学习的主要变种及其子类别: 1. 无模型 vs 有模型强化学习 无模型强化学习(Model-Free RL):代理不构建或使用环境的动态模型,而是直接通过与环境的交互来学习。 示例: Q学习(Q-Learning,包括表格化和深度Q学习) 策略梯度方法(例如,REINFORCE) Actor-Critic方法(例如A3C,PPO) 有模型强化学习(Model-Based RL):代理试图学习环境的转移动态和奖励函数,并利用这些模型来做出更有信息量的决策。 示例: Dyna-Q(Q学习与规划结合) World Models 蒙特卡洛树搜索(MCTS) 2....
