
综述六:模型量化技术
量化技术在机器学习(ML)和大型语言模型(LLM)中的应用,指的是将模型的权重和激活值的数值精度降低,通常目的是提高计算效率、减少内存占用,并加速推理过程,而不显著降低准确度。随着时间的推移,这些方法在传统机器学习和深度学习的研究中不断发展。
以下是按引入时间排序的 量化方法 列表:
1. 定点量化(Fixed-Point Quantization) (1980年代 - 1990年代初)
- 核心思想:将浮点数(32位)转换为定点数(例如16位或8位整数)。这可以减少内存需求,并加速计算,因为定点操作通常比浮点操作在硬件上更高效。
- 应用:早期的信号处理和硬件实现。
2. 向量量化(Vector Quantization)(1980年代 - 1990年代)
- 核心思想:通过使用较少的质心或码本来表示高维向量(如特征表示)。这是一种有损压缩技术,用于减少表示的维度。
- 应用:用于图像和语音压缩。
- 重要论文:Gray, “Vector Quantization and Signal Compression”, 1984。
3. 产品量化(Product Quantization) (2006)
- 核心思想:通过将向量分割成较小的子向量,并分别对每个子向量进行量化,来扩展向量量化。这减少了搜索复杂度,并提高了最近邻搜索的效率。
- 应用:大规模图像检索和特征压缩。
- 重要论文:Hervé Jégou 等人,“Product Quantization for Nearest Neighbor Search” ,2006。
4. 权重量化(Weight Quantization) (2015)
- 核心思想:将神经网络中的权重的精度从32位浮点数降低到较低位数的表示(例如8位或16位整数)。其主要目标是减少内存占用,并加速推理,特别是在专用硬件(如GPU和TPU)上。
- 应用:用于深度神经网络,使其能够更高效地部署在硬件上。
- 重要论文:Rastegari 等人,“Quantizing deep convolutional networks for efficient inference: A whitepaper” ,2016。
5. 二值量化(Binary Quantization)(2016)
- 核心思想:一种更激进的量化方法,将权重限制为两个可能的值,通常是±1。这大大减少了模型的大小和计算复杂度,因为二进制权重可以用一个比特表示。
- 应用:通常用于硬件实现中,需要极高效率的场景。
- 重要论文:Hubara 等人,“Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to +1 or -1” ,2016。
6. 三值量化(Ternary Quantization)(2017)
- 核心思想:扩展二值量化,将权重限制为三种可能的值(通常是-1、0、+1),在保持比二值量化更多信息的同时,进一步减少了内存占用。
- 应用:通常用于硬件受限的环境,如嵌入式系统或边缘设备。
- 重要论文:Zhang 等人,“Ternary Weight Networks” ,2017。
7. 量化感知训练(Quantization-Aware Training, QAT)(2017)
- 核心思想:与传统的后训练量化方法不同,QAT在训练过程中模拟低精度算术操作。这样,模型可以适应量化的影响,并减小精度损失。
- 应用:确保量化后能更好地保留准确性,尤其是对于复杂的深度神经网络。
- 重要论文:Jacob 等人,“Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference” ,2018。
8. 动态量化(Dynamic Quantization)(2018)
- 核心思想:在训练后进行量化,动态地确定每一层或激活的最佳量化方案。这可以在不修改模型的情况下对预训练模型进行量化,且无需重新训练。
- 应用:用于推理场景中,尤其是快速推理且不方便重新训练的情况。
- 重要论文:Jacob 等人,“Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference” ,2018。
9. 仅整数量化(Integer-Only Quantization)(2019)
- 核心思想:将所有操作(包括权重和激活值)转换为仅整数的算术(例如8位整数)。这使得模型可以完全在整数硬件上运行,这比浮点数运算更高效。
- 应用:通常用于在资源受限的边缘设备(如手机和物联网设备)上的部署。
- 重要论文:Rastegari 等人,“Integer-only quantization of deep convolutional networks” ,2019。
10. 低秩量化(Low-Rank Quantization)(2020)
- 核心思想:通过将权重矩阵分解为低秩组件,而不是对所有权重使用固定精度,这样可以对这些组件进行更低位的量化。这对于减少内存和计算成本特别有效。
- 应用:用于大规模神经网络,特别是变换器模型(transformer)。
- 重要论文:Shen 等人,“Low-Rank Quantization for Neural Network Compression” ,2020。
11. 后训练量化(Post-Training Quantization, PTQ)(2020)
- 核心思想:一系列技术,允许在不重新训练的情况下对预训练模型进行量化,通常使用校准集来微调量化参数(例如尺度、零点)。PTQ因其易于部署和快速回馈而变得流行。
- 应用:主要用于资源受限的环境(如边缘设备)上的部署。
- 重要论文:Choukroun 等人,“Post-Training Quantization for Neural Networks: A Survey” ,2020。
12. 变换器模型的量化(Quantization for Transformer Models)(2020-2021)
- 核心思想:专注于变换器(如BERT、GPT等)模型的高效量化。由于这些模型通常较大且占用大量内存,量化在使其能够部署在资源受限的环境中时扮演了关键角色。
- 应用:将大型语言模型(LLM)部署到手机设备和云服务等资源有限的环境中。
- 重要论文:Zafrir 等人,“Q8BERT: Quantized 8-bit BERT” ,2021。
13. 基于注意力的量化(Attention-based Quantization)(2021)
- 核心思想:一种专门针对变换器模型的量化方法,在量化过程中考虑注意力权重的重要性。这允许在不显著损失性能的情况下进行更高效的压缩。
- 应用:用于NLP任务中,尤其是变换器模型较为常见的任务。
- 重要论文:Tay 等人,“Efficient Transformers: A Survey” ,2020。
14. 混合精度量化(Mixed-Precision Quantization)(2021)
- 核心思想:为模型的不同部分使用不同的位宽。例如,某些层可能使用8位量化,而其他层使用16位,这取决于层对模型整体性能的重要性。
- 应用:优化模型大小和推理速度之间的折衷,特别是在大规模深度模型的部署中。
- 重要论文:Zhou 等人,“Mixed Precision Quantization for Deep Neural Networks” ,2021。
15. 学习量化(Learned Quantization)(2021-至今)
- 核心思想:与固定量化水平不同,学习量化技术在训练过程中学习最优的量化方案,允许根据任务和模型动态调整位宽和量化方案。
- 应用:应用于大规模神经网络(例如变换器),提高准确性保留和计算效率。
- 重要论文:Xu 等人,“Learned Quantization for Efficient Neural Network Inference” ,2021。
量化方法总结:
- 定点量化(1980年代 - 1990年代初)
- 向量量化(1980年代 - 1990年代)
- 产品量化(2006)
- 权重量化(2015)
- 二值量化(2016)
- 三值量化(2017)
- 量化感知训练(QAT)(2017)
- 动态量化(2018)
- 仅整数量化(2019)
- 低秩量化(2020)
- 后训练量化(PTQ)(2020)
- 变换器模型的量化(2020-2021)
- 基于注意力的量化(2021)
- 混合精度量化(2021)
- 学习量化(2021-至今)
这些量化方法通过逐步引入不同的技术,帮助提升深度学习模型的计算效率和内存利用率。随着计算硬件(如边缘设备、移动设备)能力的增强,以及大规模模型(如大型语言模型)的兴起,量化技术越来越成为实际部署过程中不可或缺的一部分。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Model The World!
相关推荐
2024-10-30
扩散模型中的量化、加速和采样方法
1. 量化方法 核心思想: 量化方法旨在通过将模型参数和激活值从高精度转换为低精度来减小模型大小和计算量,从而提高模型效率。例如,将 FP32 精度的参数转换为 FP16 或 INT8 精度。 工作流程: 训练: 模型量化可以在训练过程中或训练后进行。 推理: 推理阶段使用量化后的模型,通常需要特定的硬件或软件支持。 对象: 模型参数和激活值。 优缺点: 优点: 减少内存占用,允许在资源受限的设备上部署模型。 降低计算量,提高推理速度。 降低功耗,延长电池寿命(尤其适用于移动设备)。 缺点: 可能导致精度损失,需要权衡模型大小/速度和性能。 需要仔细选择量化方法和精度,以最小化精度损失。 应用: 量化方法广泛应用于各种深度学习模型中,包括扩散模型,以提高效率并使其更易于部署。 关于扩散模型量化的额外信息: 来源中没有明确提及特定于扩散模型的量化方法。有关量化方法的更多信息来自外部知识,您可能需要独立核实。 2. 加速方法 核心思想: 加速方法旨在通过减少采样过程中的迭代次数或计算量来提高扩散模型的生成速度。 工作流程: 训练:...
2024-11-23
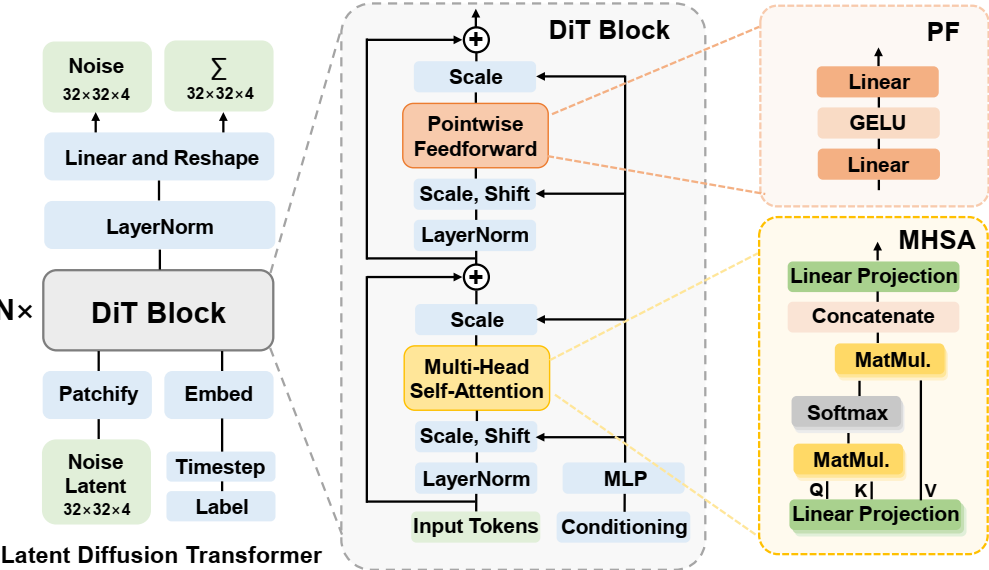
论文阅读三十八:TaQ-DiT:用于扩散Transformer的时间感知量化
摘要 基于Transformer的扩散模型,称为扩散Transformers(DiTs),已经在图像和视频生成任务中取得先进性能。然而,它们的大型模型尺寸和缓慢推理速度限制它们的实际应用,呼唤模型压缩方法,如量化。不幸地是,现有DiT量化方法忽略了(1)重建的影响和(2)跨不同层的不同的量化敏感度,阻碍它们的性能。为了解决这些问题,我们提出创新的用于DiTs的时间感知量化(TaQ-DiT)。具体地,(1)当在量化阶段分别重建权重和激活,我们观察到不收敛问题,并引入联合重建方法来解决这个问题。(2)我们发现Post-GELU激活对量化尤其敏感,因为它们在不同的去噪步骤中具有显著的可变性,并且在每个步骤中都存在极端的不对称性和变化。为此,我们提出时变感知变换来促进更有效的量化。实现结果表明,当量化DiT的权重到4位和激活到8位(W4A8)时,我们的方法显著超越先前量化方法。 引言 由于分层架构的高效性,基于 UNet 的扩散模型(DM)[1]...
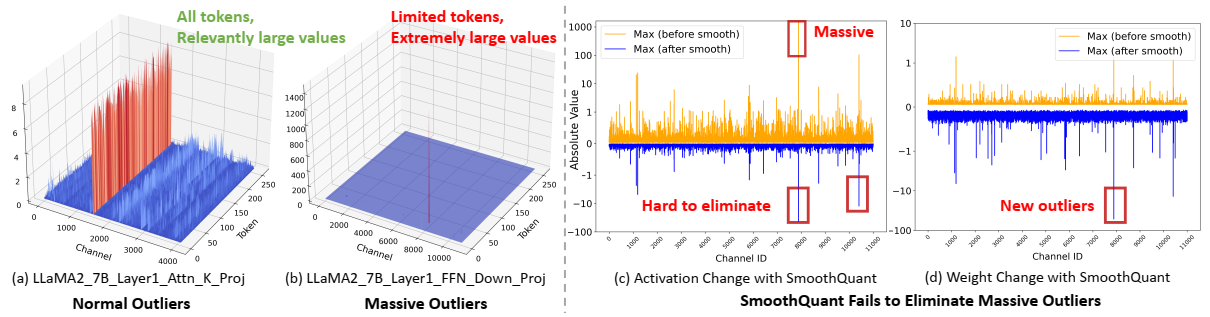
2024-11-20
论文阅读三十四:DuQuant:通过双重变换分布异常值可以增强量化LLM
大型语言模型(LLM)的量化面临着重大挑战,特别是由于存在阻碍高效低位表示的异常值激活。传统方法主要是解决正常异常值(Normal Outliers),即所有标记中具有相对较大幅度的激活。然而,这些方法难以平滑显示明显更大值的巨大异常值,这导致低位量化的性能显著下降。本文中,我们介绍DuQuant,一种新的方法,利用旋转和置换变换来更有效的消除大量和正常异常值。首先,DuQuant由构建旋转矩阵开始,使用特定的异常值维度作为先验知识,使用逐块旋转来重分布异常值到相邻通道。第二,我们进一步使用锯齿置换(zigzag permutation)来平衡块间的异常值分布,从而减少逐块方差。后续的旋转进一步平滑激活环境,增强了模型表现。DuQuant简化量化过程,且善于管理异常值,在多个任务上超越各种大小和类型的LLMs的先进基准,即便是4位权重激活量化。我们的代码在: https://github.com/Hsu1023/DuQuant...
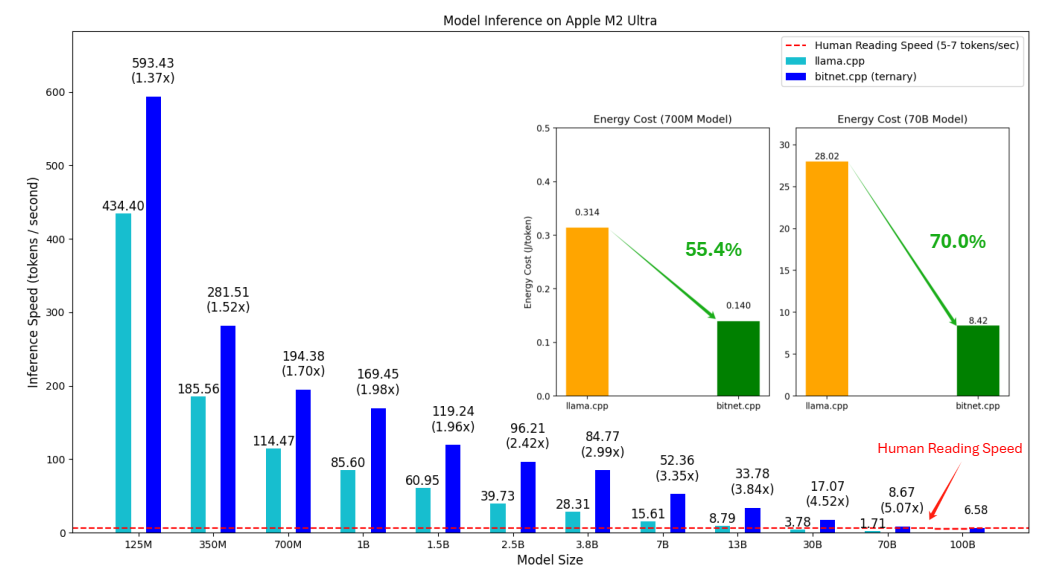
2024-11-26
论文阅读四十二:1位AI架构:部分1.1,基于GPU的快速无损BitNet b1.58推理
1位大语言模型(LLM)的最新进展,如BitNet[WMD+23]和BitNet b1.58[MWM+24],为提高LLM在速度和能耗方面的效率提供了一种有前景的方法。这些发展还使本地LLM能够在各种设备上部署。在这项工作中,我们介绍了bitnet.cpp,这是一个量身定制的软件栈,旨在释放1位LLM的全部潜力。具体来说,我们开发了一组内核来支持CPU上三进制BitNet b1.58 LLM的快速无损推理。大量的实验表明,bitnet.cpp在各种型号的CPU上实现了显著的加速,在x86 CPU上从2.37倍到6.17倍不等,在ARM CPU上从1.37倍到5.07倍不等。该代码可在 https://github.com/microsoft/BitNet 上获得。 bitnet.cpp bitnet.cpp是1位LLM(例如bitnet b1.58模型)的推理框架。它提供无损推理,同时优化速度和能耗。bitnet.cpp的初始版本支持CPU上的推理。 如图1所示,bitnet.cpp在ARM...
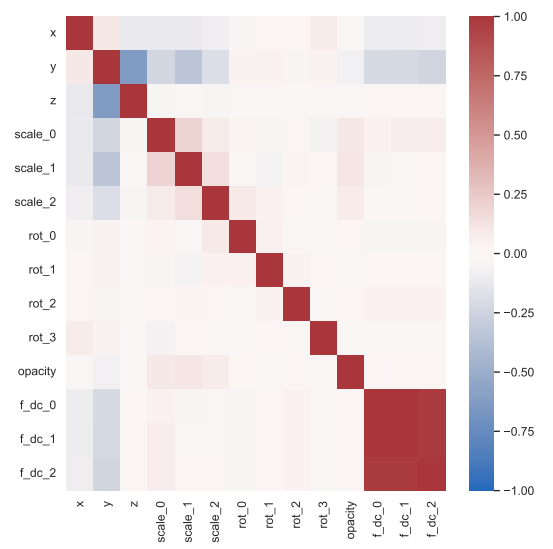
2024-12-07
论文阅读四十七:3DGS.zip:3D高斯泼溅压缩方法综述
摘要 3D 高斯泼溅(3DGS)已成为实时辐射场渲染的前沿技术,提供质量和速度的先进性能。3DGS将场景建模为三维高斯的集合,或“泼溅”,以及额外的属性优化以符合场景的集合和视觉特性。尽管它在渲染速度和图像保真度中的优势,3DGS受到其显著的存储和内存需要的限制。这些高需求使得3DGS对于移动设备或耳机不实际,减少它在计算机图形学重要领域中的应用。为解决这些挑战,并促进3DGS的实用,该先进报告(STAR)提供综合和细致的关于3DGS更加有效的压缩和压实技术的检测。我们分类当前方法为压缩技术,旨在以最小数据量获得的最高质量,和压实技术,旨在使用最少的高斯取得最优质量。我们介绍了所分析方法背后的基本数学概念,以及关键的实现细节和设计选择。我们的报告深入讨论了这些方法之间的异同,以及它们各自的优缺点。我们根据关键性能指标和数据集建立了比较这些方法的一致标准。具体而言,由于这些方法是在短时间内并行开发的,目前还没有全面的比较。这项调查首次提出了评估3DGS压缩技术的统一标准。为了促进对新兴方法的持续监测,我们维护了一个专门的网站,该网站将定期更新新技术和对现有发现的修订...
2024-11-24
综述一:Transformer及其变体
Transformer架构,因其自注意力机制而闻名,能够让模型根据输入序列中不同的标记之间的关系进行加权。这种机制消除了循环神经网络的需求,使得训练变得更加高效。自从2017年原始Transformer的提出以来,已经出现了多个变种,旨在优化性能、扩展其适用范围或解决一些挑战。以下是一些著名的Transformer变种,特别是那些专注于自注意力机制的: 1. 原始Transformer (Vanilla Transformer) 关键特性:原始Transformer架构包括一个编码器-解码器结构,采用自注意力机制。 目的:消除了递归神经网络的需求,使得模型训练更加并行化和高效。 自注意力机制:多头自注意力,通过计算输入序列中所有标记之间的关系来决定重要性。 2. BERT(双向编码器表示) 关键特性:BERT只使用Transformer的编码器部分,采用双向自注意力机制来捕获标记的左右上下文。 目的:通过掩蔽语言模型(MLM)进行预训练,并可以通过微调来提升在下游NLP任务中的表现。 3....
