
论文阅读四十:大型视觉编码器的多模态自回归预训练
摘要
我们引入一种用于大型视觉编码器预训练的新方法。基于视觉模型自回归预训练的最新进展,我们扩展该架构到多模态设置,即,图像和文本。本文中,我们展示AIMv2,一组通用视觉编码器,特点是简单的预训练、可扩展性,和一系列下游任务中的卓越的性能。其实现是通过将视觉编码器和多模态解码器配对,自回归地生成原始图像块和文本标记。我们的编码器不仅在多模态评估方面表现出色,而且在定位、接地(grounding)和分类等视觉基准方面也表现出色。值得注意的是,我们的 AIMV2-3B 编码器在 ImageNet-1k 的冻结躯干上达到了 89.5% 的准确率。此外,AIMV2 在不同环境下的多模态图像理解方面始终优于最先进的对比模型(如 CLIP、SigLIP)。 论文地址
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Model The World!
相关推荐
2024-11-03
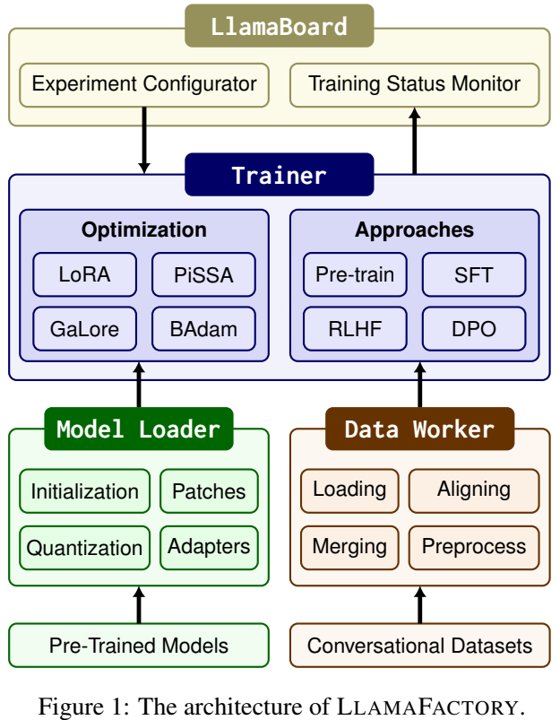
论文阅读七:LLaMA-Factory:100多种语言模型的统一高效微调
摘要 高效的微调对于使大型语言模型(LLM)适应下游任务至关重要。然而,在不同的模型上实现这些方法需要付出巨大的努力。我们介绍LLAMAFACTORY,这是一个整合了一套尖端高效训练方法的统一框架。它提供了一种解决方案,可以灵活地定制100多个LLM的微调,而无需通过内置的web UI LLAMABOARD进行编码。我们实证验证了我们的框架在语言建模和文本生成任务上的效率和有效性。它已发布于 https://github.com/hiyouga/LLaMA-Factory ,并获得了25000多颗星和3000个fork。 引言 大型语言模型(LLM)(赵等人,2023)具有显著的推理能力,并赋予了广泛的应用,如问答(Jiang等人,2023b)、机器翻译(Wang等人,2023c;Jiao等人,2023a)和信息提取(Jiao等人(2023b))。随后,大量LLM被开发出来,并可通过开源社区访问。例如,Hugging...
2024-11-10
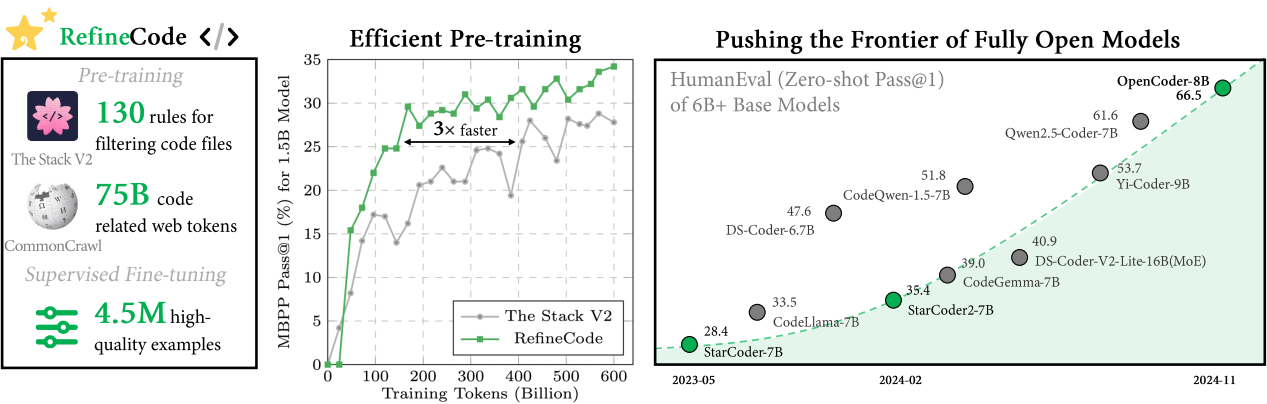
论文阅读九:OPENCODER:顶级代码LLM的开放手册
...
2024-11-16
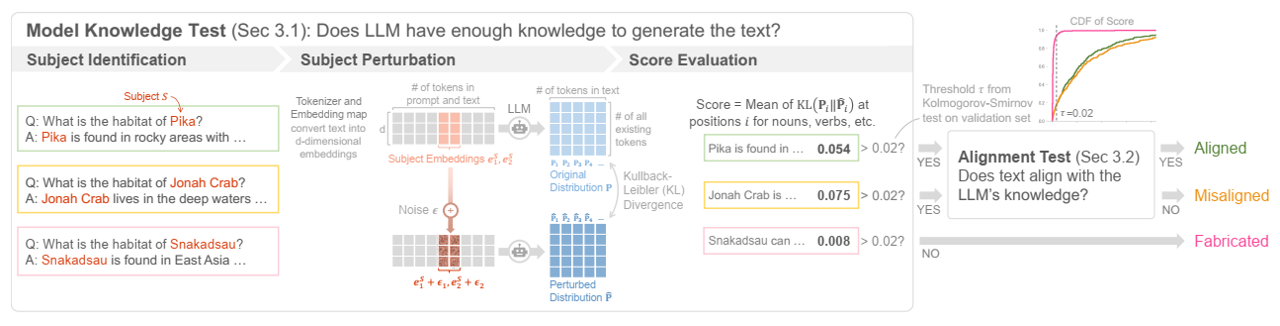
论文阅读二十三:基于零样本知识测试的LLM幻觉推理
摘要 LLM幻觉,LLM偶尔会产生不忠实的文本,对其实际应用构成了重大挑战。大多数现有的检测方法依赖于外部知识、LLM微调或幻觉标记的数据集,并且它们不能区分不同类型的幻觉,而幻觉对于提高检测性能至关重要。我们引入了一个新的任务,幻觉推理,它将LLM生成的文本分为三类:对齐、未对齐和伪造。我们新颖的零样本方法评估LLM是否对给定的提示和文本有足够的知识。我们在新数据集上进行的实验证明了我们的方法在幻觉推理中的有效性,并强调了它对提高检测性能的重要性。...
2024-11-16
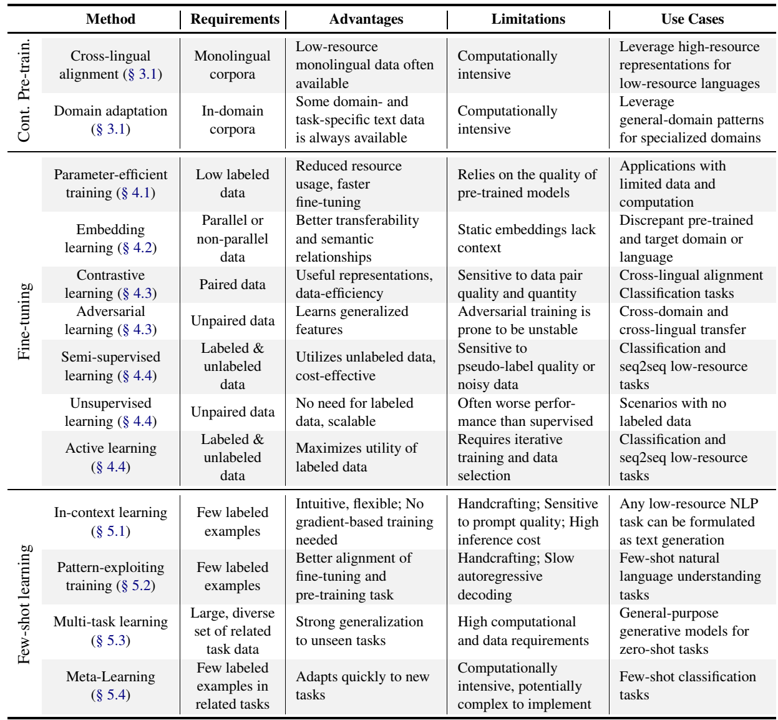
论文阅读二十二:有限数据微调语言模型实用指南
摘要 使用预训练大型语言模型(LLMs)已经称为自然语言处理(NLP)中的事实标准,尽管它们需要大量数据。受最近以有限数据训练LLM为重点的研究激增的启发,特别是在低资源领域和语言中,本文调查了最近的迁移学习方法,以优化数据稀缺的下游任务中的模型性能。我们首先解决初始化和持续的预训练策略,以更好地利用未知领域和语言的先验知识。然后,我们研究如何在微调和少样本学习过程中最大限度地利用有限的数据。最后一节从特定任务的角度,回顾了适用于不同数据稀缺程度的模型和方法。我们的目标是为从业者提供实用的指导方针,以克服数据受限带来的挑战,同时突出未来研究的有前景的方向。论文地址 引言 预训练语言模型(PLMs)正在改变NLP领域,显示出学习和建模来自复杂和多样化领域的自然语言数据底层分布的出色能力(Han等人,2021)。然而,他们的训练需要大量的数据和计算资源,这在许多现实世界场景中可能是令人望而却步的(Bai et al.,2024),尤其是对于英语以外的语言和专业领域,例如医学(Crema et al.,2023;Van Veen et al.,2021)、化学(Jablonka et...
2024-11-16
论文阅读二十四:Squeezed Attention:加速长上下文长度LLM推理
...
2024-11-14
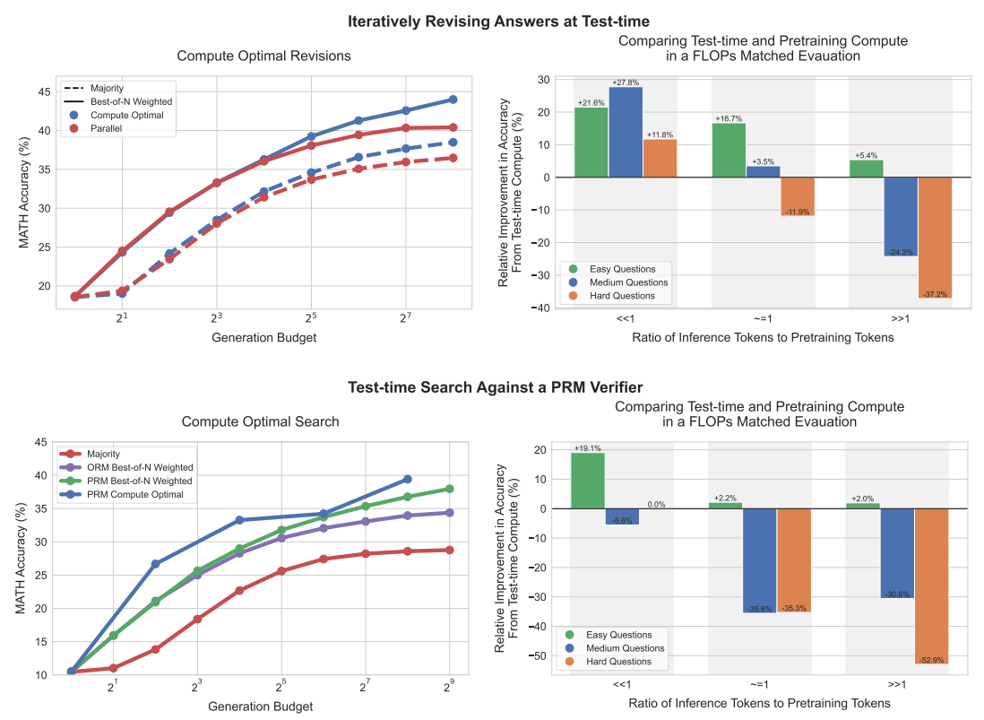
论文阅读二十:优化缩放LLM测试时间计算比缩放模型参数更有效
使LLM能够通过使用更多的测试时间计算来提高其输出,是构建可以在开放式自然语言上运行的一般自我改进代理的关键一步。本文研究了LLM中推理时间计算的缩放,重点回答了以下问题:如果允许LLM使用固定但非微不足道的推理时间计算,那么它在具有挑战性的提示下能提高多少性能?回答这个问题不仅对LLM的可实现性能有影响,而且对LLM预训练的未来以及如何权衡推理时间和预训练计算也有影响。尽管它很重要,但很少有研究试图了解各种测试时间推理方法的缩放行为。此外,目前的工作在很大程度上为其中一些策略提供了负面结果。在这项工作中,我们分析了两种主要的机制来扩展测试时间计算:(1)针对密集的、基于过程的验证者奖励模型进行搜索;以及(2)在测试时给出提示的情况下自适应地更新模型在响应上的分布。我们发现,在这两种情况下,缩放测试时间计算的不同方法的有效性因提示的难度而异。这一观察结果促使应用...
