
论文阅读四十九:大型概念模型:句子表示空间中的语言建模
摘要
LLMs彻底改变了人工智能领域,并已成为许多任务的事实工具。目前建立的LLM技术是在token级别处理输入并生成输出。这与人类在多个抽象层次上操作形成鲜明对比,远远超出了单个单词的范围,以分析信息并生成创造性内容。在本文中,我们提出了一种尝试,即一种在显式的高级语义表示上运行的架构,我们称之为“概念”。概念与语言和情态无关,代表流中更高层次的想法或行为。因此,我们构建了一个“大概念模型”。在这项研究中,作为可行性的证明,我们假设一个概念对应于一个句子,并使用现有的句子嵌入空间SONAR,它在文本和语音模式中支持多达200种语言。
训练大概念模型以在嵌入空间中执行自回归句子预测。我们探索了多种方法,即MSE回归、基于扩散的生成变体以及在量化SONAR空间中运行的模型。这些探索是使用1.6B参数模型和1.3T标记顺序的训练数据进行的。然后,我们将一个架构扩展到7B个参数的模型大小和约2.7T标记的训练数据。我们对几个生成任务进行了实验评估,即摘要和摘要扩展的新任务。最后,我们证明了我们的模型对许多语言表现出令人印象深刻的零样本泛化性能,优于相同大小的现有LLMs。我们模型的训练代码是免费提供的。 代码
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Model The World!
相关推荐
2024-11-02
论文阅读三:生成的表示对齐(REPA):训练扩散变换器比你想象的要容易
...
2024-11-01
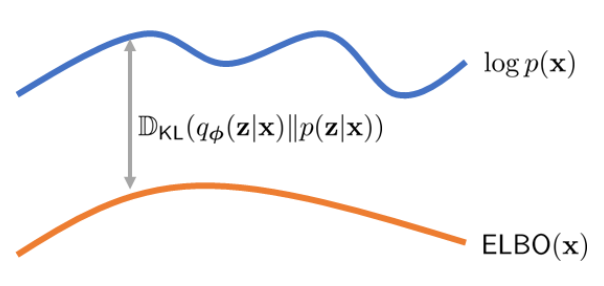
论文阅读二:成像和视觉扩散模型教程
...
2024-10-31
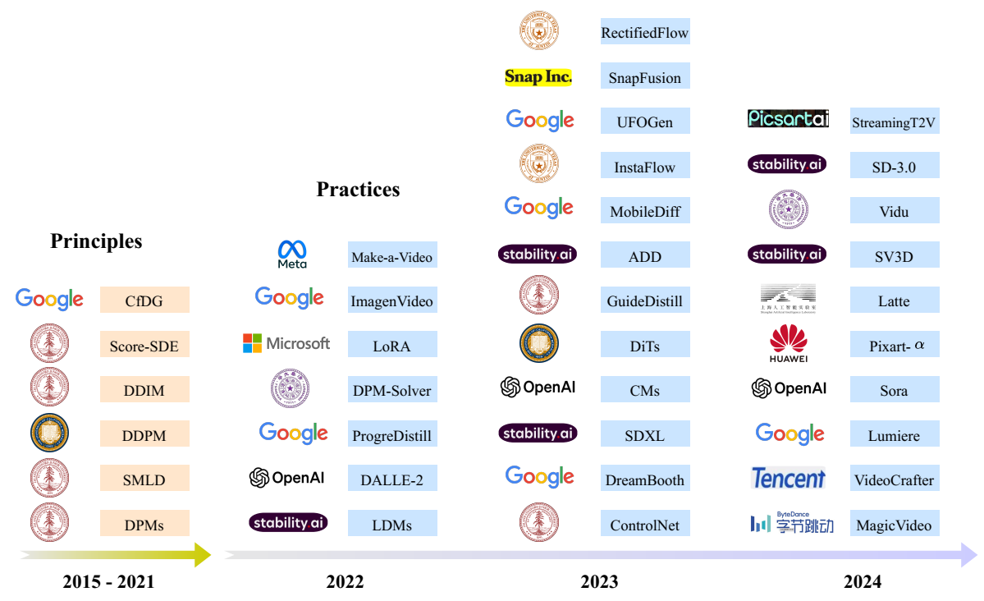
论文阅读一:高效扩散模型:从原理到实践的全面综述
...
2024-11-03
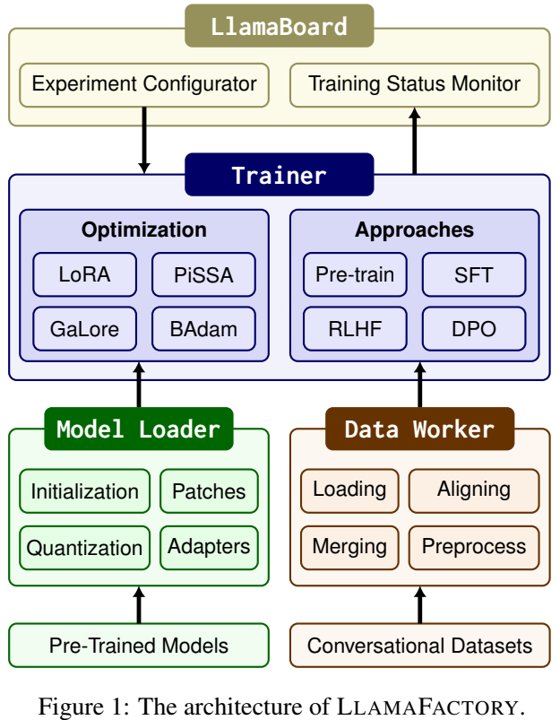
论文阅读七:LLaMA-Factory:100多种语言模型的统一高效微调
摘要 高效的微调对于使大型语言模型(LLM)适应下游任务至关重要。然而,在不同的模型上实现这些方法需要付出巨大的努力。我们介绍LLAMAFACTORY,这是一个整合了一套尖端高效训练方法的统一框架。它提供了一种解决方案,可以灵活地定制100多个LLM的微调,而无需通过内置的web UI LLAMABOARD进行编码。我们实证验证了我们的框架在语言建模和文本生成任务上的效率和有效性。它已发布于 https://github.com/hiyouga/LLaMA-Factory ,并获得了25000多颗星和3000个fork。 引言 大型语言模型(LLM)(赵等人,2023)具有显著的推理能力,并赋予了广泛的应用,如问答(Jiang等人,2023b)、机器翻译(Wang等人,2023c;Jiao等人,2023a)和信息提取(Jiao等人(2023b))。随后,大量LLM被开发出来,并可通过开源社区访问。例如,Hugging...

2024-11-18
论文阅读三十一:3D高斯溅射用于实时辐射场渲染
辐射场方法最近彻底改变了用多张照片或视频捕获的场景的新颖视图合成。然而,实现高视觉质量仍然需要训练和渲染成本高昂的神经网络,而最近更快的方法不可避免地会以速度换取质量。对于无界和完全场景(不是独立物体)和1080p分辨率渲染,当前没有方法可以取得实时显示速率。我们引入三个关键因素,允许我们取得先进视觉质量,同时保持有竞争力的训练次数,并且重要的是,允许1080分辨率的高质量实时( ≥30fps\ge 30 fps≥30fps...
2024-11-23
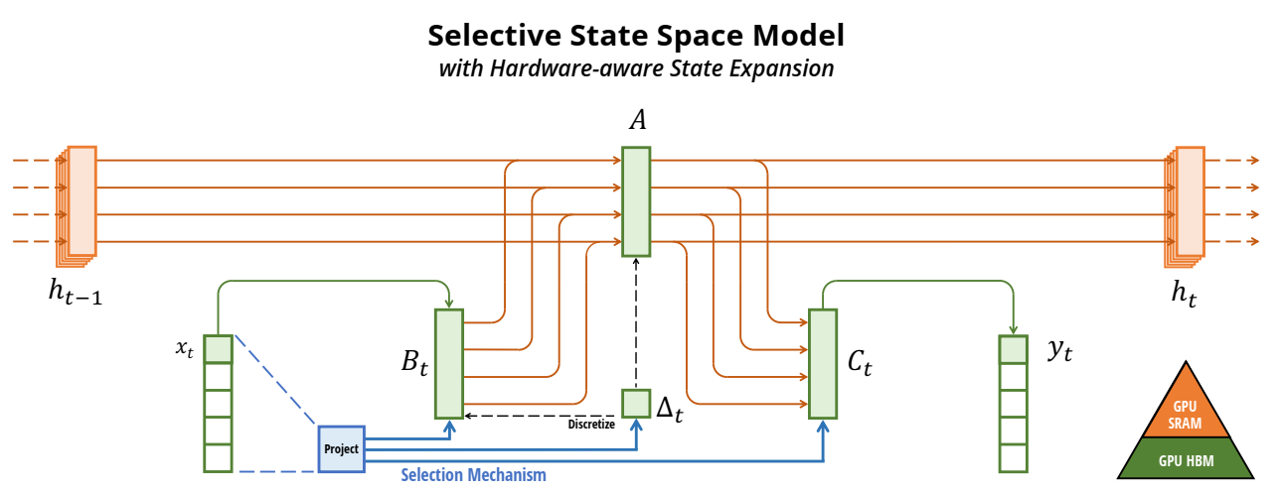
论文阅读三十七:Mamba:具有选择性状态空间的线性时间序列建模
...
