
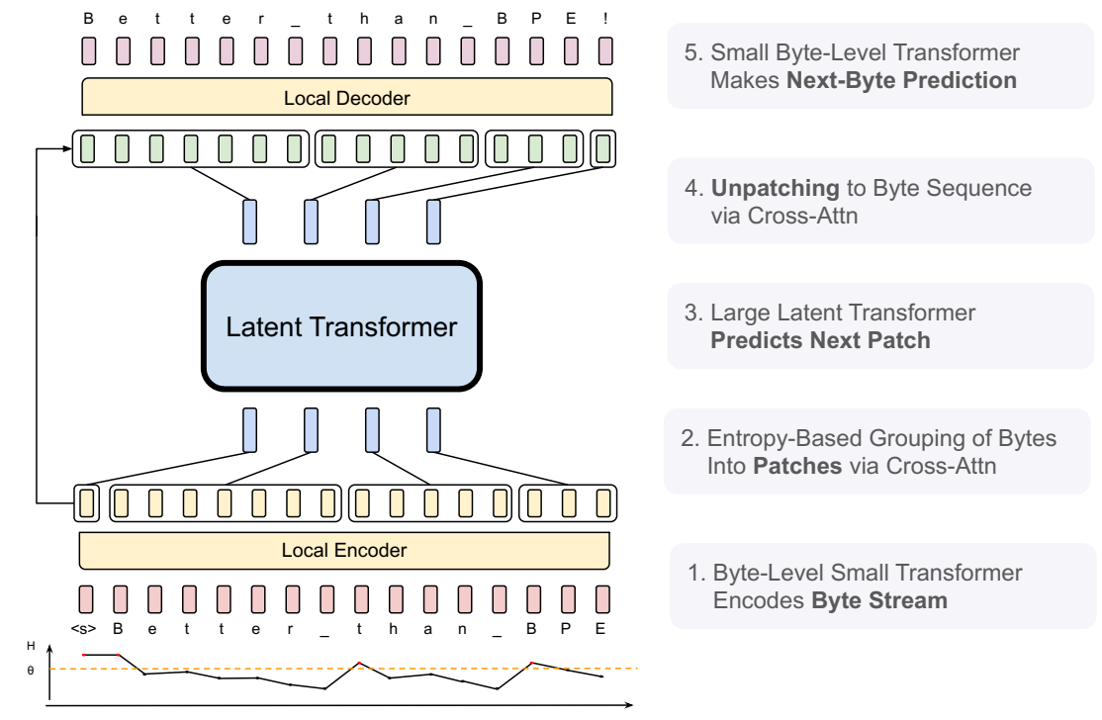
论文阅读五十:字节潜在Transformer:Patches比Tokens扩展性好
摘要 我们介绍了Byte Latent...
论文阅读四十八:免训练图神经网络和标签作为特征的力量
摘要 我们提出免训练图神经网络(TFGNNs),无需训练即可使用,也可以使用选择性的训练来改善,对于转导节点分类。我们首先提倡标签即特征(LaF),这是一种可接受但尚未探索的技术。我们证明了LaF可证明地增强了图神经网络的表达能力。我们基于这一分析设计了TFGNN。在实验中,我们证实了TFGNN在无训练环境中优于现有的GNN,并且比传统的GNN收敛的训练迭代次数少得多。 论文地址
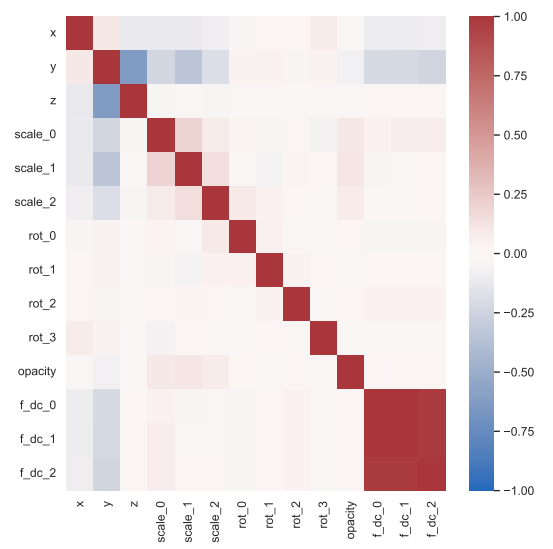
论文阅读四十七:3DGS.zip:3D高斯泼溅压缩方法综述
摘要 3D 高斯泼溅(3DGS)已成为实时辐射场渲染的前沿技术,提供质量和速度的先进性能。3DGS将场景建模为三维高斯的集合,或“泼溅”,以及额外的属性优化以符合场景的集合和视觉特性。尽管它在渲染速度和图像保真度中的优势,3DGS受到其显著的存储和内存需要的限制。这些高需求使得3DGS对于移动设备或耳机不实际,减少它在计算机图形学重要领域中的应用。为解决这些挑战,并促进3DGS的实用,该先进报告(STAR)提供综合和细致的关于3DGS更加有效的压缩和压实技术的检测。我们分类当前方法为压缩技术,旨在以最小数据量获得的最高质量,和压实技术,旨在使用最少的高斯取得最优质量。我们介绍了所分析方法背后的基本数学概念,以及关键的实现细节和设计选择。我们的报告深入讨论了这些方法之间的异同,以及它们各自的优缺点。我们根据关键性能指标和数据集建立了比较这些方法的一致标准。具体而言,由于这些方法是在短时间内并行开发的,目前还没有全面的比较。这项调查首次提出了评估3DGS压缩技术的统一标准。为了促进对新兴方法的持续监测,我们维护了一个专门的网站,该网站将定期更新新技术和对现有发现的修订...
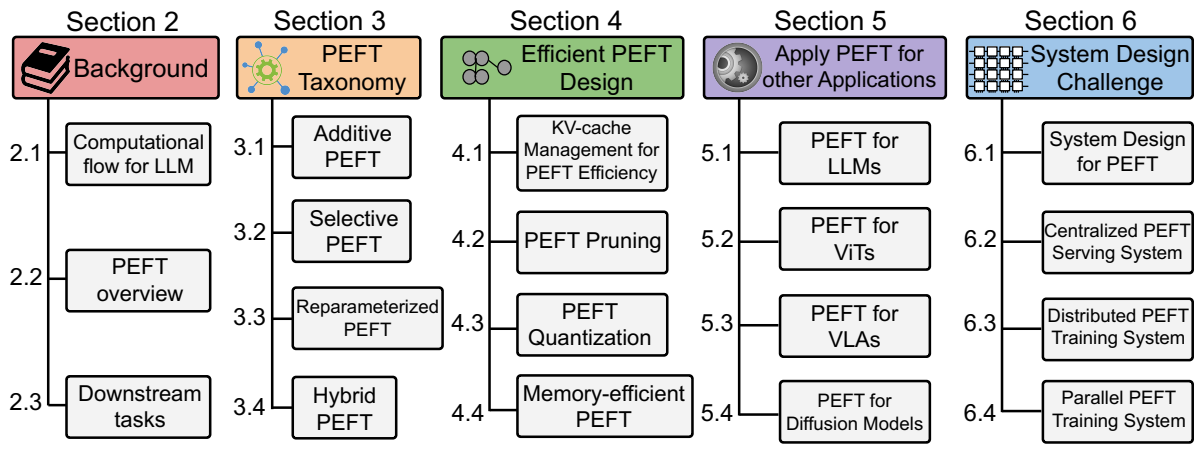
综述十一:大模型微调方法
大型语言模型微调方法详解(SFT、PT、RM、PPO、DPO 和 KTO) 以下是对几种关键的大型语言模型(LLM)微调方法的比较,包括重要的“RM”(奖励模型)。 1. SFT(监督式微调) 核心思想: 经典的监督学习。使用输入-输出对(提示和期望的回复)的数据集训练 LLM。 数据: 带有清晰的示例,说明模型应该如何回应的标记数据。 过程: 调整 LLM 的权重,以最大限度地减少其预测与数据集中正确答案之间的差异。 优点: 易于实现,通常提供强大的基线性能。 缺点: 需要高质量的标记数据,在捕捉细微的人类偏好或复杂的任务方面可能效果较差。 2. PT(提示微调) 核心思想: 不是大幅度改变 LLM 的权重,而是在输入中添加一小组“提示”参数。 数据: 类似于 SFT,使用输入-输出对。 过程: 只训练提示参数,引导 LLM 给出更好的回应,而不改变其核心知识。 优点: 非常节省参数,适用于资源有限的情况。 缺点: 对于非常复杂的任务,可能无法达到与完全微调(SFT)相同的性能水平。 3. RM(奖励模型) 核心思想: 训练一个单独的模型来预测给定 LLM...
综述十二:视频生成模型
模型 STIV:Scalable Text and Image Conditioned Video Generation (24/12) 论文地址 核心思想:视频生成领域取得了显著进展,但仍然迫切需要一个清晰、系统的配方来指导稳健和可扩展模型的开发。在这项工作中,我们提出了一项全面的研究,系统地探讨了模型架构、训练配方和数据管理策略的相互作用,最终提出了一种简单且可扩展的文本图像条件视频生成方法,称为STIV。我们的框架通过帧替换将图像条件集成到扩散Transformer(DiT)中,同时通过图像-文本条件无分类的联合引导引入文本条件。这种设计使STIV能够同时执行文本到视频(T2V)和文本图像到视频(TI2V)任务。此外,STIV可以很容易地扩展到各种应用,如视频预测、帧插值、多视图生成和长视频生成等。通过对T2I、T2V和TI2V的全面消融研究,STIV尽管设计简单,但表现出了强大的性能。分辨率为5122的8.7B型号在VBench...
综述十:多模态模型
模型 基础模型 LLaVA: Visual Instruction Tuning (23/04) 论文地址 代码 核心思想:指令调优大型语言模型(LLMs)使用机器生成指令遵循数据,被证明在新任务上提升零样本能力,但这一想法在多模态领域的探索较少。提出第一个尝试,使用仅语言GPT-4来生成多模态语言图像指令遵循数据。通过在这种生成数据上指令调优,引入LLaVA:大型语言和视觉助手,一种端到端训练的大型多模态模型,连接视觉编码器和LLM,用于通用用途视觉和语言理解。为促进在视觉指令遵循上的进一步研究,构建两个具有多样性和挑战性的面向应用任务的评估基准。 Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond...
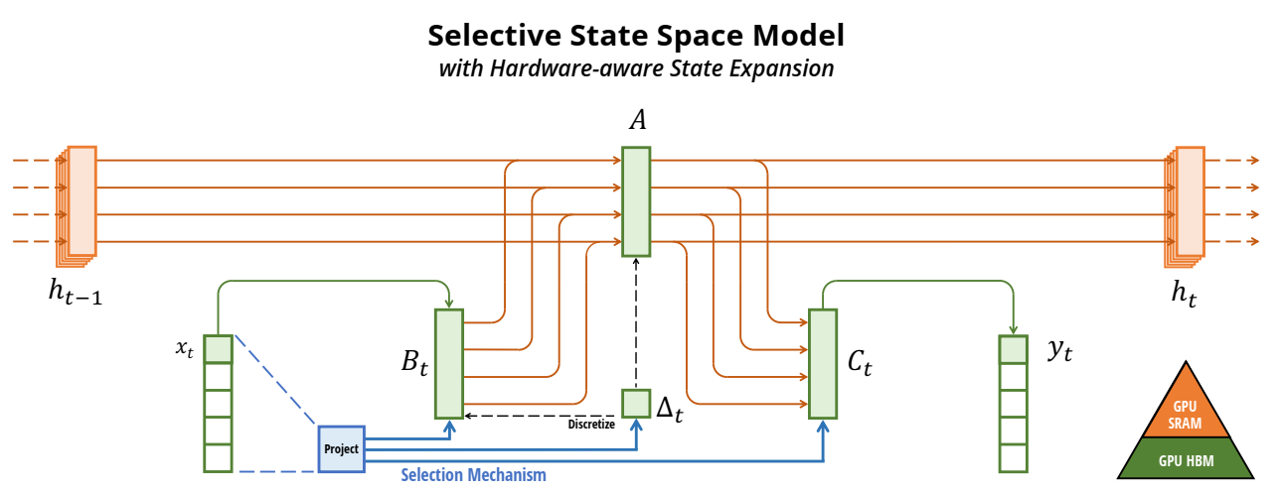
论文阅读四十五:流式深度强化学习
摘要 自然智能以连续流的方式处理经验,每时每刻都在实时感知、行动和学习。流式学习是Q-learning和TD等经典强化学习(RL)算法的工作方式,它通过使用最新样本而不存储来模仿自然学习。这种方法也非常适合资源受限、通信受限和隐私敏感的应用程序。然而,在深度 RL 中,学习者几乎总是使用批量更新和重放缓冲区,这使得它们的计算成本很高,而且与流式学习不兼容。虽然批量深度 RL 的盛行通常归因于其采样效率,但流式深度 RL 的缺失还有一个更关键的原因,那就是它经常出现不稳定性和学习失败,我们称之为流式障碍。本文介绍了stream-x 算法,它是第一类在预测和控制方面都克服了流障碍的深度 RL 算法,并且与批处理 RL 的样本效率相匹配。通过在 Mujoco Gym、DM Control Suite 和 AtariGames 中的实验,我们证明了现有算法中的流障碍,并利用我们的stream-x算法:流 Q、流 AC 和流 TD 成功实现了稳定学习,在 DM Control Dog...
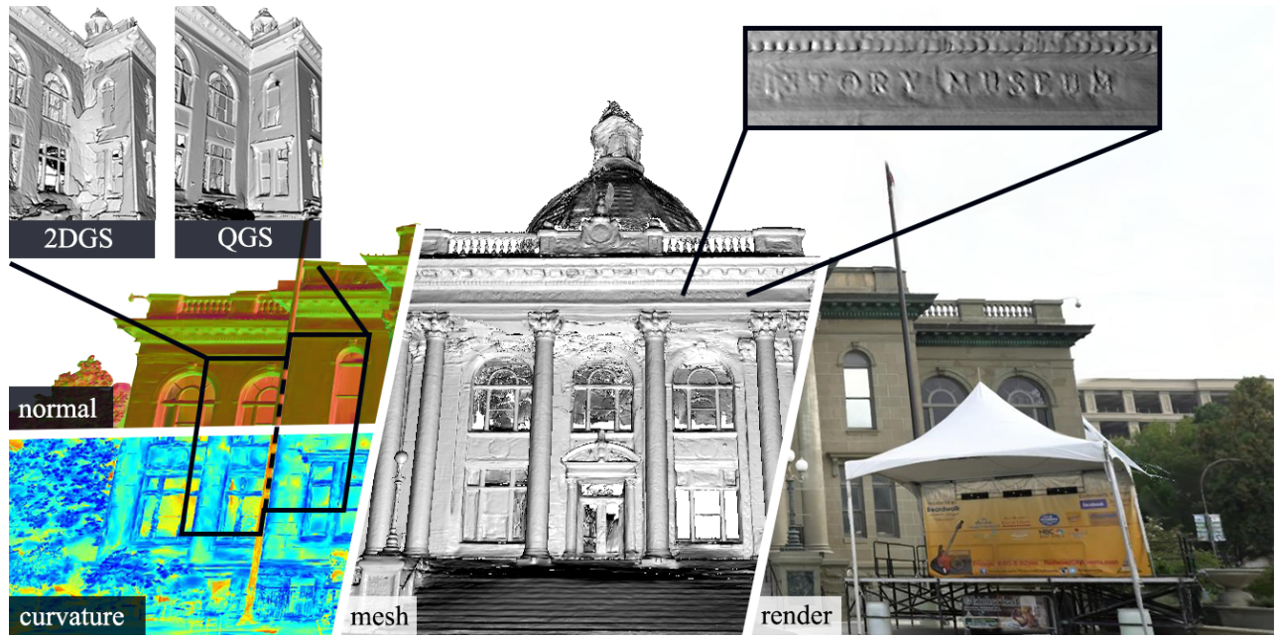
论文阅读四十四:用于高效细致曲面重建的二次高斯泼溅
摘要 最近,3D高斯泼溅(3DGS)因其在神经辐射场(NeRF)之上的卓越的渲染质量和速度而受到关注。为了解决3DGS在曲面表示中的限制,2D高斯泼溅(2DGS)引入圆盘(disks)作为场景基元,来建模和重构来自多视图图像的几何图形。然而,圆盘的一阶线性近似常常导致过平滑的结果。我们提出二次高斯泼溅(QGS),一种新方法,它用二次曲面替代圆盘,增强了几何拟合。QGS在非欧空间定义高斯分布,允许基元捕获更复杂的纹理。作为二阶曲面近似,QGS还渲染空间曲率来指导法线一致性项,来有效减少过平滑。而且,QGS是2DGS的泛化版本,取得更准确和细致的重建,已由DTU和TNT上的实验验证,展示了它超越了几何重建中大多数先进方法的有效性。我们的代码将会作为开源发布。项目在:...
