
论文阅读四十三:测试时高效学习:LLMs的主动微调
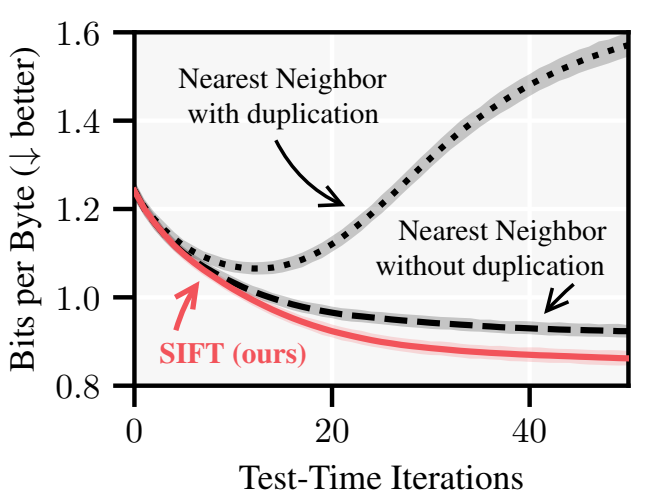
摘要 微调语言模型的近期努力常常依赖于自动数据选择,通常使用来自大型数据集的最近邻检索。然而,我们理论性说明,这种方法倾向于选择冗余数据,限制了它的效率,甚至有损性能。为此,我们引入SIFI,一种数据选择算法,旨在减少给定提示模型响应的不确定性,它统一了来自检索和主动学习的思想。鉴于最近邻检索常常在存在信息重复时失败,SIFT考虑到信息重复,并优化选择样本的整体信息增益。我们的评估重点是在测试时对Pile数据集上的提示特定语言建模进行微调,并表明SIFT在计算开销最小的情况下始终优于最近邻检索。此外,我们证明了我们的不确定性估计可以预测测试时间微调的性能增益,并利用这一点开发了一种自适应算法,该算法将测试时间计算与实现的性能增益成比例。我们提供了activeft(主动微调)库,可以作为最近邻检索的直接替代品。 论文地址
论文阅读四十二:1位AI架构:部分1.1,基于GPU的快速无损BitNet b1.58推理
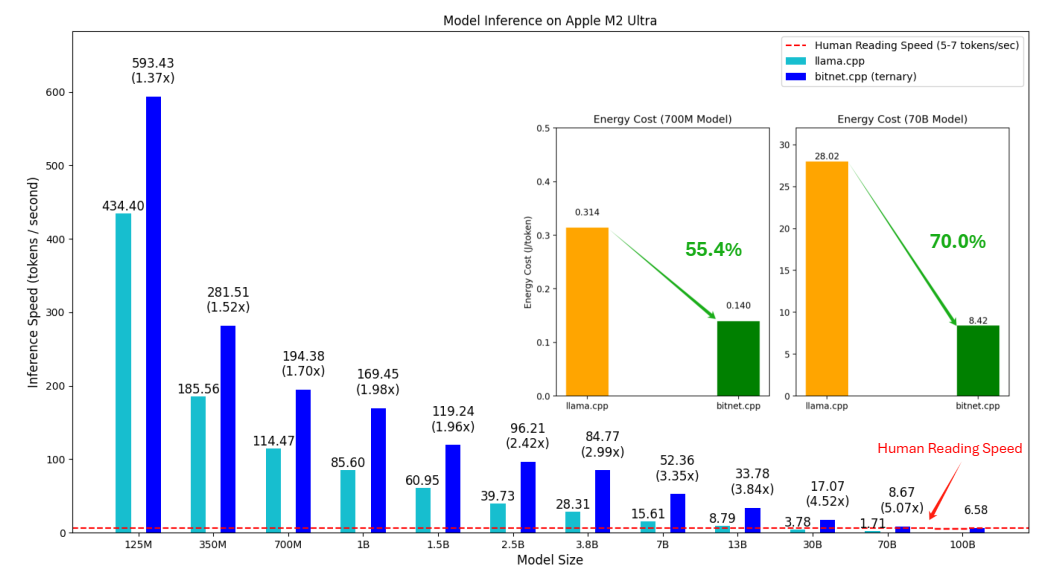
1位大语言模型(LLM)的最新进展,如BitNet[WMD+23]和BitNet b1.58[MWM+24],为提高LLM在速度和能耗方面的效率提供了一种有前景的方法。这些发展还使本地LLM能够在各种设备上部署。在这项工作中,我们介绍了bitnet.cpp,这是一个量身定制的软件栈,旨在释放1位LLM的全部潜力。具体来说,我们开发了一组内核来支持CPU上三进制BitNet b1.58 LLM的快速无损推理。大量的实验表明,bitnet.cpp在各种型号的CPU上实现了显著的加速,在x86 CPU上从2.37倍到6.17倍不等,在ARM CPU上从1.37倍到5.07倍不等。该代码可在 https://github.com/microsoft/BitNet 上获得。 bitnet.cpp bitnet.cpp是1位LLM(例如bitnet b1.58模型)的推理框架。它提供无损推理,同时优化速度和能耗。bitnet.cpp的初始版本支持CPU上的推理。 如图1所示,bitnet.cpp在ARM...

论文阅读四十:大型视觉编码器的多模态自回归预训练
摘要 我们引入一种用于大型视觉编码器预训练的新方法。基于视觉模型自回归预训练的最新进展,我们扩展该架构到多模态设置,即,图像和文本。本文中,我们展示AIMv2,一组通用视觉编码器,特点是简单的预训练、可扩展性,和一系列下游任务中的卓越的性能。其实现是通过将视觉编码器和多模态解码器配对,自回归地生成原始图像块和文本标记。我们的编码器不仅在多模态评估方面表现出色,而且在定位、接地(grounding)和分类等视觉基准方面也表现出色。值得注意的是,我们的 AIMV2-3B 编码器在 ImageNet-1k 的冻结躯干上达到了 89.5% 的准确率。此外,AIMV2 在不同环境下的多模态图像理解方面始终优于最先进的对比模型(如 CLIP、SigLIP)。 论文地址
论文阅读三十九:SAMURAI:用于零样本视觉追踪的具有运动感知记忆的自适应SAM
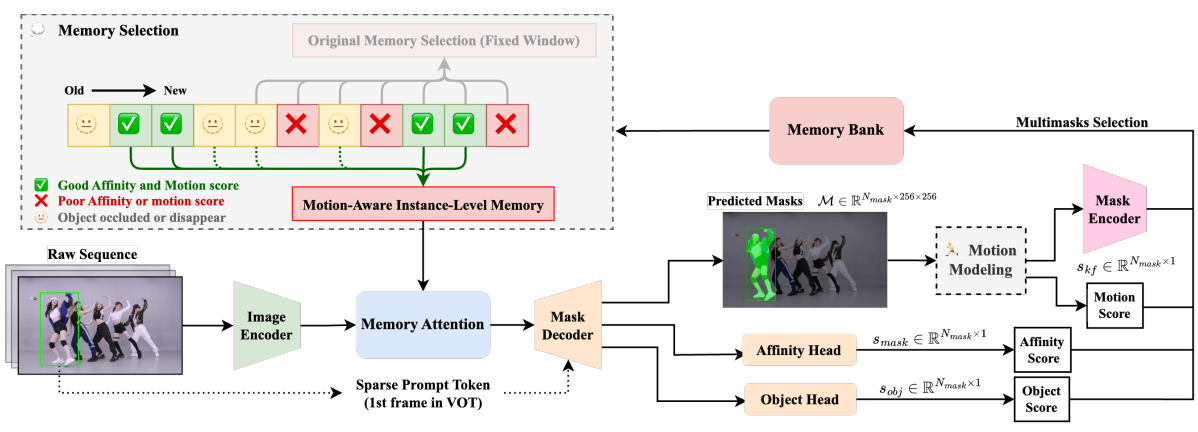
摘要 分割一切模型 2(SAM2)在目标分割任务上已经展示强大性能,但在视觉目标追踪中面临挑战,尤其当处理具有快速移动或自遮挡的物体的拥挤场景时。此外,原始模型中固定窗口的记忆方法未考虑选择用于下一帧调节的图像特征的记忆的质量,导致视频中的误差传播。本文介绍SAMURAI,SAM2的增强适应性版,专为视觉目标跟踪而设计。通过结合时间运动线索和提出的运动感知记忆选择机制,SAMURAI有效地预测目标运动,并优化掩码选择,无需再训练或微调,取得稳健精确追踪。SAMURAI实时操作,并在各种基准数据集上展示强大的零样本性能,说明了它的无需微调的泛化能力。评估中,SAMURAI在现有追踪器的成功率和精度上取得显著改进, LaSOTextLaSOT_{ext}LaSOText上增益为 7.1%, GOT-10k上增益3.5%。而且,它相较于LaSOT上的全监督方法取得竞争性的结果,突出了它在复杂追踪场景的健壮性,以及它在真实世界动态环境应用上的潜力。代码和结果在: https://github.com/yangchris11/samurai...
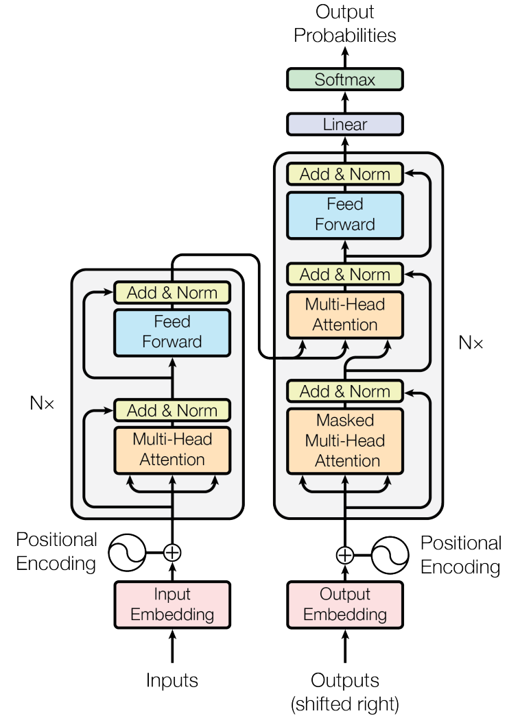
综述一:Transformer及其变体
Transformer架构,因其自注意力机制而闻名,能够让模型根据输入序列中不同的标记之间的关系进行加权。这种机制消除了循环神经网络的需求,使得训练变得更加高效。自从2017年原始Transformer的提出以来,已经出现了多个变种,旨在优化性能、扩展其适用范围或解决一些挑战。以下是一些著名的Transformer变种,特别是那些专注于自注意力机制的: 1. 原始Transformer (Vanilla Transformer) 关键特性:原始Transformer架构包括一个编码器-解码器结构,采用自注意力机制。 目的:消除了递归神经网络的需求,使得模型训练更加并行化和高效。 自注意力机制:多头自注意力,通过计算输入序列中所有标记之间的关系来决定重要性。 2. BERT(双向编码器表示) 关键特性:BERT只使用Transformer的编码器部分,采用双向自注意力机制来捕获标记的左右上下文。 目的:通过掩蔽语言模型(MLM)进行预训练,并可以通过微调来提升在下游NLP任务中的表现。 3....
综述七:CNN模型
Here’s a list of major CNN (Convolutional Neural Network) variants ordered by the time of their publication. CNNs have evolved over the years to improve accuracy, reduce computational costs, and adapt to different domains. 1. LeNet (1998) Key Idea: One of the first CNN architectures, designed for handwritten digit recognition (MNIST). It used convolutional layers followed by pooling and fully connected layers. Application: Digit classification. Notable Paper: Yann LeCun et al.,...
综述三:持续学习及其方法
持续学习(Continual Learning,CL),也称为终身学习(Lifelong Learning),指的是模型能够从持续不断的数据流中学习,并随着时间的推移不断适应和获得新知识,而不会遗忘先前学习的内容。持续学习面临的一个主要挑战是灾难性遗忘(Catastrophic Forgetting),即在学习新任务时,模型容易遗忘之前学习的任务。 为了应对这些挑战,提出了多种方法,这些方法可以根据它们如何处理遗忘、如何存储知识以及如何使用新数据进行分类。 下面是主要的持续学习方法,按它们所采用的主要策略进行组织: 1....
综述九:LLM
提示(Prompts) Large Lanuage Models Can Self-Improve in Long-context Reasoning (24/10) 论文地址 核心思想:大型语言模型(LLM)在处理长上下文方面取得了实质性进展,但在长上下文推理方面仍存在困难。现有的方法通常涉及使用合成数据对LLM进行微调,这取决于人类专家的注释或GPT-4等高级模型,从而限制了进一步的进步。为了解决这个问题,研究了LLM在长上下文推理中自我改进的潜力,并提出了专门为此目的设计的SEALONG方法。这种方法很简单:对每个问题的多个输出进行采样,用最小贝叶斯风险对其进行评分,然后根据这些输出进行监督微调或偏好优化。在几个领先的LLM上进行的广泛实验证明了SEALONG的有效性,Llama-3.1-8B-Instruct的绝对提高了4.2分。此外,与依赖于人类专家或高级模型生成的数据的先前方法相比,SEALONG实现了更优的性能。我们预计,这项工作将为长期情景下的自我提升技术开辟新的途径,这对LLM的持续发展至关重要。
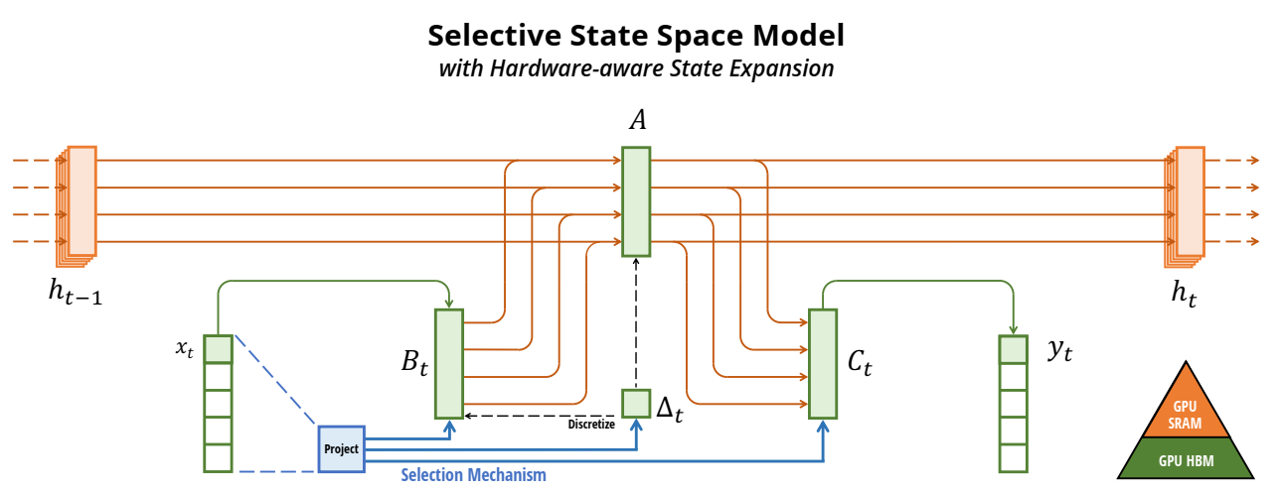
综述九:Mamba及其变体
SSM模型 Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (20/06) 论文地址 核心思想:将自注意表示为核特征图的线性点积,并使用矩阵乘法的结合属性将复杂度从 O(N2)\mathcal{O}(N^2)O(N2) 减少到 O(N)\mathcal{O}(N)O(N) ,其中N是序列长度。我们证明,这个公式允许迭代实现,大大加速了自回归Transformers,并揭示了它们与循环神经网络的关系。(一种涉及循环的自我注意近似,可以看作是退化的线性SSM) Hungry Hungry Hippos: Towards Language Modeling with State Space Models...
