

综述二:DiTs及其变体
**DiT(去噪扩散Transformer模型)**是结合了Transformer架构和扩散模型的一类生成模型,特别专注于在扩散框架内的去噪过程。扩散模型通过逐步添加和去除噪声的过程来建模复杂的分布,近年来在生成任务中非常流行。 下面是一些著名的DiT变种,它们在不同方面扩展了原始的DiT模型: 1. DiT(原始版本) 关键特性:原始的DiT模型将Transformer架构与去噪扩散过程结合,利用Transformer的注意力机制改进生成质量和训练的可扩展性。 目的:生成高质量的图像,并与传统的卷积神经网络相比,提高训练效率。 2. DiT++(增强版DiT) 关键特性:DiT++是在原始DiT基础上进行增强的版本,可能包括模型架构的改进、训练方法的优化或额外的正则化技术。 目的:通过改进Transformer架构和扩散过程中的噪声调度,提升生成稳定性和性能。 3....
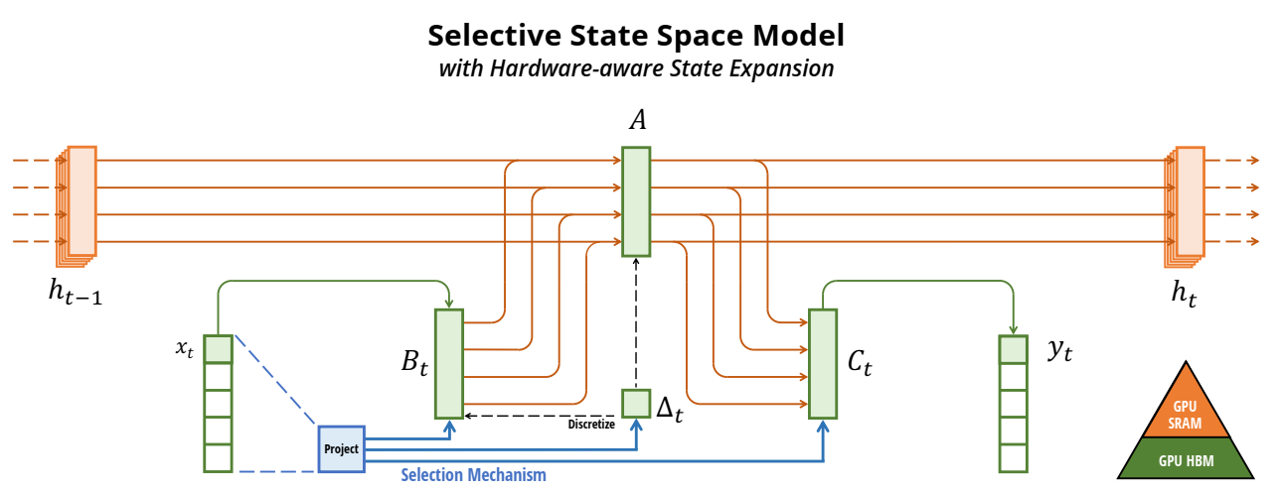
综述五:强化学习及其分类
强化学习的变种 强化学习(Reinforcement Learning,简称RL)是一种机器学习方法,其中代理(Agent)通过与环境的交互来学习做出决策。代理的目标是通过采取适当的行动,最大化长期累积的奖励。强化学习是一个广泛的领域,许多不同的变种和算法已被开发出来,以解决学习、探索和决策等不同方面的问题。 以下是强化学习的主要变种及其子类别: 1. 无模型 vs 有模型强化学习 无模型强化学习(Model-Free RL):代理不构建或使用环境的动态模型,而是直接通过与环境的交互来学习。 示例: Q学习(Q-Learning,包括表格化和深度Q学习) 策略梯度方法(例如,REINFORCE) Actor-Critic方法(例如A3C,PPO) 有模型强化学习(Model-Based RL):代理试图学习环境的转移动态和奖励函数,并利用这些模型来做出更有信息量的决策。 示例: Dyna-Q(Q学习与规划结合) World Models 蒙特卡洛树搜索(MCTS) 2....
综述八:高斯泼溅
模型 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (20/03) 论文地址 核心思想:提出一种方法,通过使用一组稀疏输入视图,优化底层的连续体积场景函数,取得合成复杂场景的新颖视图的先进结果。该算法使用全连接(非卷积)深度网络来表示场景,其输入是单一连续5D坐标(空间位置(x,y,z) 和视图方向 (θ,ϕ)(\theta,\phi)(θ,ϕ) )且其输出是该空间位置的体积密度和视图相关辐射亮度(view-dependent emitted radiance)。通过查询沿相机光线的5D坐标,并使用经典体积渲染技术将输出颜色和密度投影到图像来合成视图。因为体积渲染天然可微,优化表示所需的唯一输入是一组已知相机位姿的图像。 Instant Neural Graphics Primitives with a Multiresolution Hash Encoding...
综述六:模型量化技术
量化技术在机器学习(ML)和大型语言模型(LLM)中的应用,指的是将模型的权重和激活值的数值精度降低,通常目的是提高计算效率、减少内存占用,并加速推理过程,而不显著降低准确度。随着时间的推移,这些方法在传统机器学习和深度学习的研究中不断发展。 以下是按引入时间排序的 量化方法 列表: 1. 定点量化(Fixed-Point Quantization) (1980年代 - 1990年代初) 核心思想:将浮点数(32位)转换为定点数(例如16位或8位整数)。这可以减少内存需求,并加速计算,因为定点操作通常比浮点操作在硬件上更高效。 应用:早期的信号处理和硬件实现。 2. 向量量化(Vector Quantization)(1980年代 - 1990年代) 核心思想:通过使用较少的质心或码本来表示高维向量(如特征表示)。这是一种有损压缩技术,用于减少表示的维度。 应用:用于图像和语音压缩。 重要论文:Gray, “Vector Quantization and Signal Compression”, 1984。 3. 产品量化(Product...
综述四:Yolo系列及其变体
YOLO(You Only Look Once)是最著名的目标检测系列之一,由Joseph Redmon及其团队开发。YOLO的核心特点是速度快,因为它采用单次前向传递进行目标检测,比许多其他检测模型要快。随着时间的推移,YOLO经历了多个版本的迭代和改进,每个版本都在精度、速度和处理不同应用场景的能力上有所提升。 以下是YOLO的主要版本及其变种的列表: 1. YOLOv1(2015年) 关键特性: YOLO的第一个版本。 提出了一个单一的神经网络来进行端到端的目标检测。 将目标检测视为回归问题,直接从图像中预测边界框和类别概率。 变种: Tiny YOLOv1:YOLOv1的轻量版,优化了速度,牺牲了精度,适用于实时应用和低资源设备。 局限性: 对小物体和密集场景的检测较差。 定位精度比当时的其他方法差。 2. YOLOv2(2016年) —...
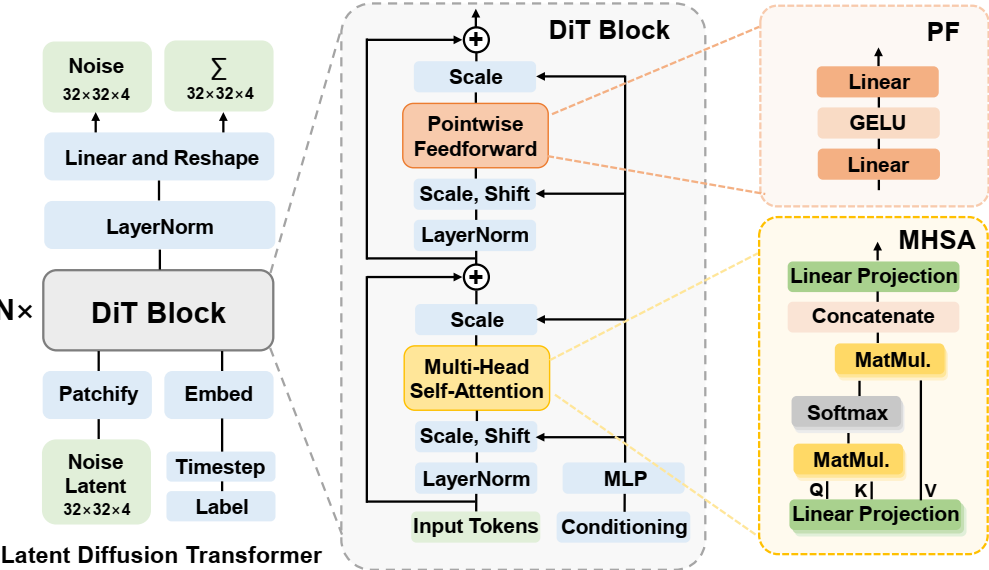
论文阅读三十八:TaQ-DiT:用于扩散Transformer的时间感知量化
摘要 基于Transformer的扩散模型,称为扩散Transformers(DiTs),已经在图像和视频生成任务中取得先进性能。然而,它们的大型模型尺寸和缓慢推理速度限制它们的实际应用,呼唤模型压缩方法,如量化。不幸地是,现有DiT量化方法忽略了(1)重建的影响和(2)跨不同层的不同的量化敏感度,阻碍它们的性能。为了解决这些问题,我们提出创新的用于DiTs的时间感知量化(TaQ-DiT)。具体地,(1)当在量化阶段分别重建权重和激活,我们观察到不收敛问题,并引入联合重建方法来解决这个问题。(2)我们发现Post-GELU激活对量化尤其敏感,因为它们在不同的去噪步骤中具有显著的可变性,并且在每个步骤中都存在极端的不对称性和变化。为此,我们提出时变感知变换来促进更有效的量化。实现结果表明,当量化DiT的权重到4位和激活到8位(W4A8)时,我们的方法显著超越先前量化方法。 引言 由于分层架构的高效性,基于 UNet 的扩散模型(DM)[1]...
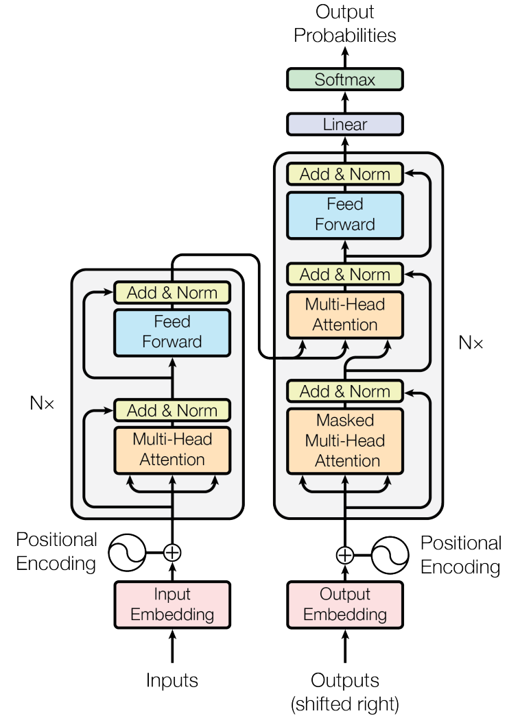
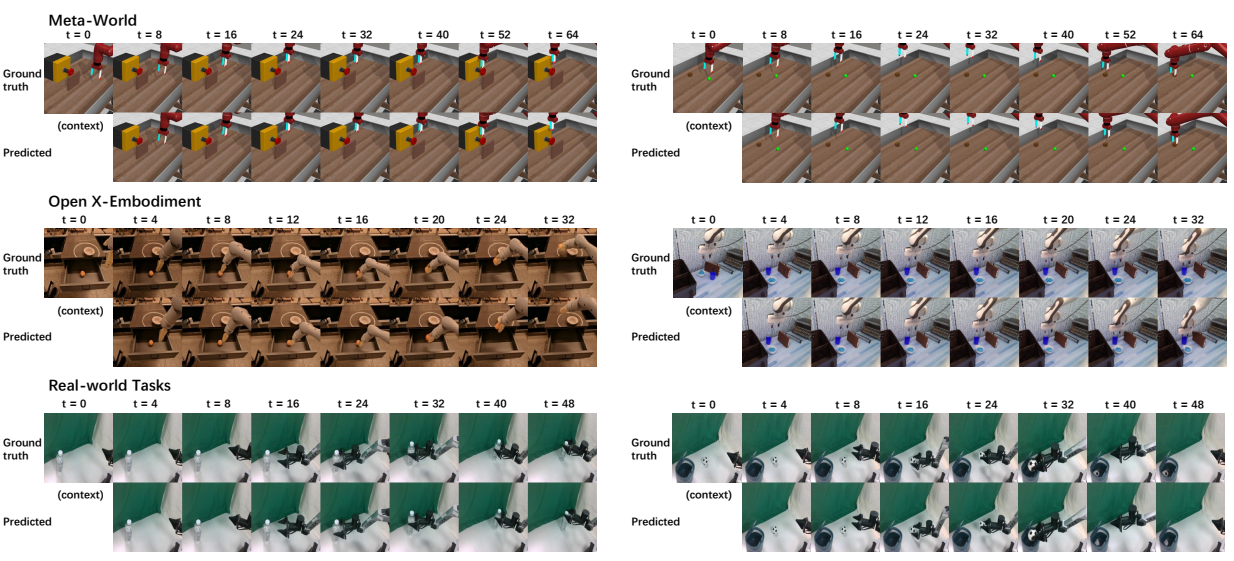
论文阅读三十五:WHALE:面向具身决策的可推广和可扩展的世界模型
摘要 世界模型在具身环境的决策中至关重要,实现无成本的探索,若在真实世界将是昂贵的。为了促进有效决策,世界模型必须具备强大的泛化能力来支持分布外(OOD)区域的忠实想象,且提供可靠的不确定性估计来评估模拟经验的置信度,两者都都先前扩展方法提出了重大挑战。本文引入WHALE,学习可泛化世界模型的框架,包含两种关键技术:行为调节(behavior-conditioning)和回溯推断(retracing-rollout)。行为调节解决策略分布漂移,世界模型泛化误差的主要来源之一,而回溯推断无需模型集成可实现有效的不确定性估计。这些技术是通用的,可以与任意神经网络架构结合来进行世界模型学习。结合这两种技术,我们推出Whale-ST,一个可扩展的基于时空transformer的世界模型,具有强大的泛化能力。我们展示了Whale-ST 在模拟任务中的优越性,通过评估值估计精度和视频生成保真度。此外,我们测试了我们不确定估计技术的有效性,它在全离线场景中增强了基于模型的策略优化。进一步地,我们提出Whale-X,一个414M参数世界模型,在来自 Open...
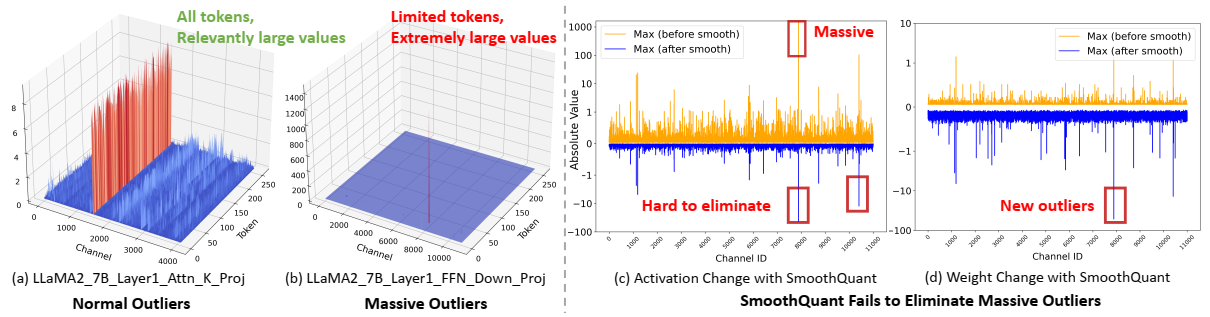
论文阅读三十四:DuQuant:通过双重变换分布异常值可以增强量化LLM
大型语言模型(LLM)的量化面临着重大挑战,特别是由于存在阻碍高效低位表示的异常值激活。传统方法主要是解决正常异常值(Normal Outliers),即所有标记中具有相对较大幅度的激活。然而,这些方法难以平滑显示明显更大值的巨大异常值,这导致低位量化的性能显著下降。本文中,我们介绍DuQuant,一种新的方法,利用旋转和置换变换来更有效的消除大量和正常异常值。首先,DuQuant由构建旋转矩阵开始,使用特定的异常值维度作为先验知识,使用逐块旋转来重分布异常值到相邻通道。第二,我们进一步使用锯齿置换(zigzag permutation)来平衡块间的异常值分布,从而减少逐块方差。后续的旋转进一步平滑激活环境,增强了模型表现。DuQuant简化量化过程,且善于管理异常值,在多个任务上超越各种大小和类型的LLMs的先进基准,即便是4位权重激活量化。我们的代码在: https://github.com/Hsu1023/DuQuant...
