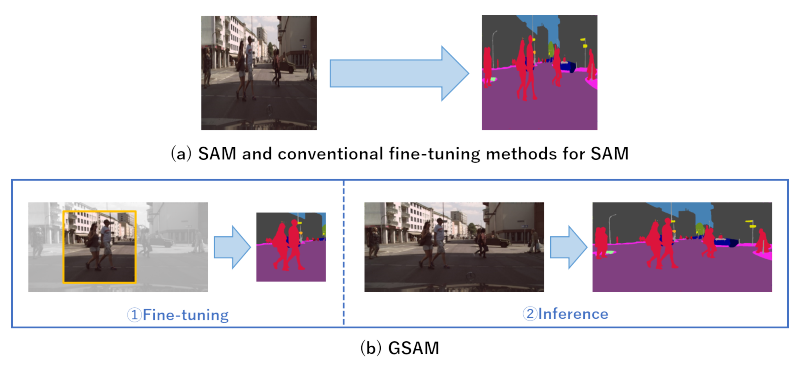
论文阅读三十二:广义SAM:可变输入图像尺寸的SAM的高效微调
摘要 有大量近期研究关于改进微调基础模型的效率。本文中,我们提出一种新颖的高效微调方法,允许SAM的输入图像大小是可变的。SAM是用于图像分割的强大基础模型,训练在巨大数据集上,但它需要微调来识别任意类别。SAM的输入图像尺寸固定在 1024×10241024\times 10241024×1024 ,导致训练中的大量计算需求。此外,固定输入图像尺寸可能导致图像信息损失,即,由于固定的宽高比。为解决这个问题,我们提出广义SAM(GSAM)。不同于先前方法,GSAM是第一个在SAN训练中应用随机裁剪,从而显著降低训练的计算成本。在各种类型和各种像素数的数据集上进行的实验表明,GSAM 可以比 SAM 和其他 SAM 微调方法更有效地进行训练,实现相当或更高的准确率。我们的代码: https://github.com/usagisukisuki/G-SAM...

论文阅读三十一:3D高斯溅射用于实时辐射场渲染
辐射场方法最近彻底改变了用多张照片或视频捕获的场景的新颖视图合成。然而,实现高视觉质量仍然需要训练和渲染成本高昂的神经网络,而最近更快的方法不可避免地会以速度换取质量。对于无界和完全场景(不是独立物体)和1080p分辨率渲染,当前没有方法可以取得实时显示速率。我们引入三个关键因素,允许我们取得先进视觉质量,同时保持有竞争力的训练次数,并且重要的是,允许1080分辨率的高质量实时( ≥30fps\ge 30 fps≥30fps...
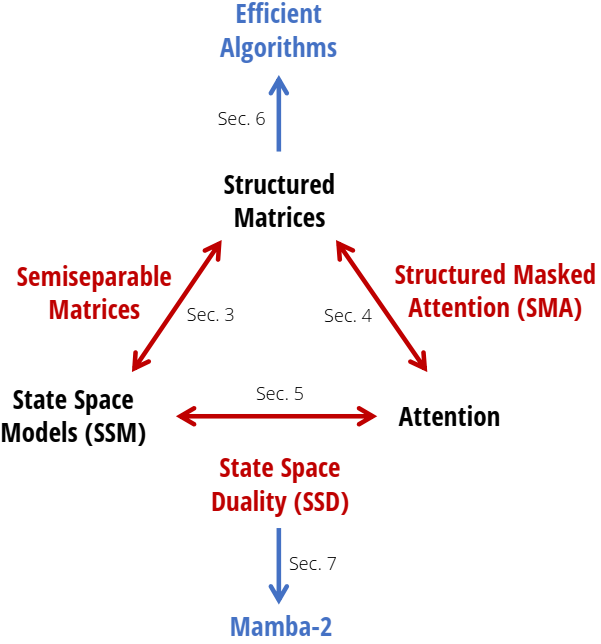
论文阅读三十:Mamba2:Transformers are SSMs
摘要 虽然Transformers已经成为深度学习在语言建模中成功的主要架构,状态空间模型(SSMs),如Mamba,近期被证明在小到中尺寸匹配或超越Transformers。我们证明,这些模型系列实际上是非常紧密相关的,并在SSMs和注意力变体之间开发一个丰富的理论联系框架,通过对一类研究良好的结构化半可分矩阵的各种分解来联系。我们的状态空间对偶性(SSD)框架允许我们设计新的架构(Mamba-2),其核心层是Mamba的选择性SSM的优化,速度快2-8倍,同时继续在语言建模中与Transformers具有可比性。...

论文阅读二十九:Llama3
当今人工智能(AI)系统由基础模型驱动。本文介绍一组新的基础模型,称为Llama3。它是一群语言模型,原生支持多语言、编码、推理和工具使用。我们最大的模型是具有405B参数和上下文窗口达到128K标记的密集Transformer。本文展示Llama3的大量实验评估。我们发现,Llama3在大量任务上提供了与GPT-4等领先语言模型相当的质量。我们公开发布Llama3,包括预训练和后训练的405B参数语言模型和我们用于输入和输出安全的Llama Guard 3模型版本。本文还介绍了我们通过组合方法将图像、视频和语音功能集成到Llama3中的实验结果。我们观察到,这种方法在图像、视频和语音识别任务上与最先进的技术具有竞争力。结果模型尚未广泛发布,因为它们仍在开发中。 Website:...
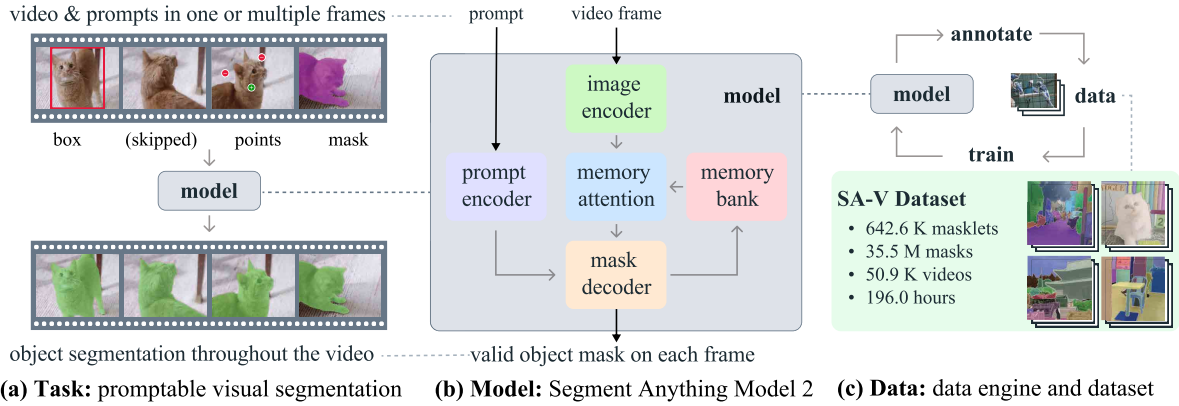
论文阅读二十八:SAM2:分割图像和视频中的任何内容
我们提出分割一切模型SAM2,是解决图像和视频中快速视觉分割的基础模型。我们构建一个数据引擎,通过用户交互改进模型和数据,来收集迄今为止最大规模的视频分割数据集。我们的模型是简单的transformer架构,对于实时视频处理具有流式内存。SAM2在我们数据上训练,提供跨广泛任务范围的强大的性能。在视频分割中,我们观测到比先前方法更好的准确度,使用3倍少的的交互。在图像分割,我们的模型更加准确,且6倍快于SAM模型。我们相信我们的数据、模型和见解将成为视频分割及其相关感知任务的重要里程碑。 演示: https://sam2.metademolab.com 代码: https://github.com/facebookresearch/sam2 网站:...
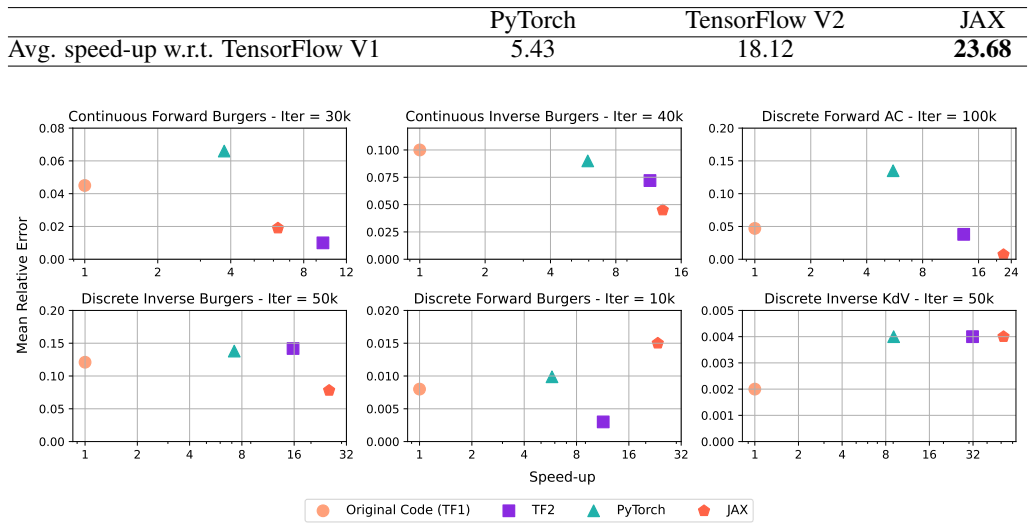
论文阅读二十七:PINNs跨框架比较:JAX、TENSORFLOW和PYTORCH
摘要 物理信息神经网络(PINNs,Physics-Informed Neural Networks)已经成为用于遵循物理定律并解决非线性偏微分方程(PDEs)的关键技术。提高PINN实现的性能可以显著加快模拟的速度,并促进创新方法的创建。本文介绍了“PINNs-JAX”,这是一个创新的实现,它利用JAX框架来利用XLA编译器的独特功能。这种方法旨在提高PINN应用程序中的计算效率和灵活性。我们对PINN-JAX与TensorFlow V1、TensorFlow V2和PyTorch等广泛使用的框架中的传统PINN实现进行了全面比较,评估了六个不同示例的性能。这些问题包括连续问题、离散问题、正问题和逆问题。我们的研究结果表明,用JAX实现的PINN在更简单的例子中表现更好,但TensorFlow V2在应对大规模挑战方面具有潜在的优势,正如3D Navier-Stokes案例所示。为了支持协作开发和进一步研究,我们已将源代码公开于: https://github.com/rezaakb/pinns-jax...
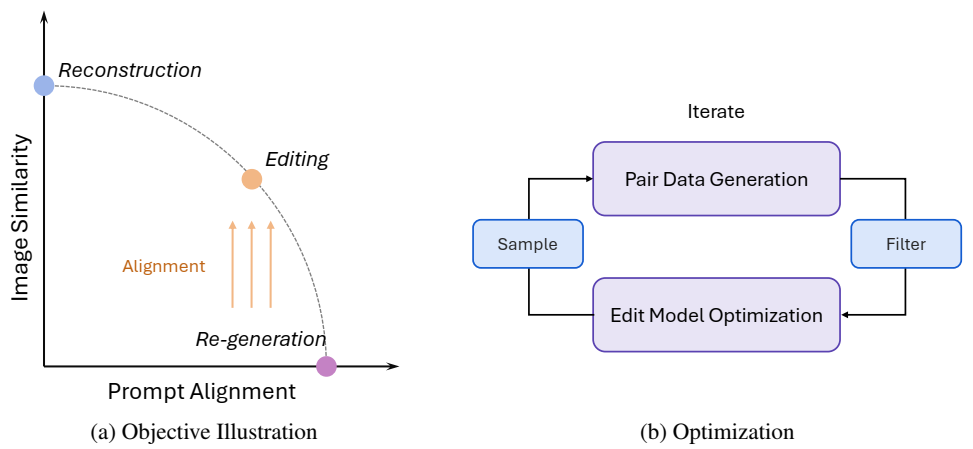
论文阅读二十六:SEEDEDIT:将图像重新生成与图像编辑对齐
摘要 我们引入SeedEdit,一个扩散模型,可以使用任意文本提示修改给定图像。在我们看来,这项任务的关键是在保持原始图像(即图像重建)和生成新图像(即,图像再生成)之间获得最佳平衡。为此,我们从一个弱生成器(文本到图像模型)开始,在这两个方向之间创建不同的对,并逐渐将其对齐为一个强图像编辑器,在两个任务之间实现良好的平衡。SeedEdit可以实现比以前的图像编辑方法更多样化、更稳定的编辑能力,从而能够对扩散模型生成的图像进行连续修改。我们的网站是 https://team.doubao.com/seededit...
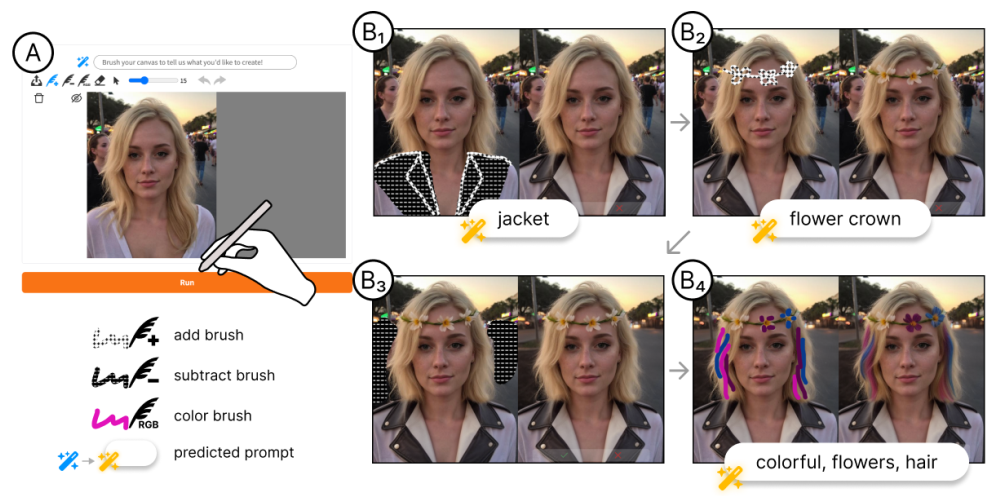
论文阅读二十五:MagicQuill:一个智能交互式图像编辑系统
摘要 作为一种高度实用的应用程序,图像编辑会遇到各种用户需求,因此优先考虑出色的易用性。在本文中,我们推出了MagicQuill,这是一个集成的图像编辑系统,旨在支持用户快速实现他们的创造力。我们的系统从一个流线型但功能强大的界面开始,使用户只需几笔就能表达他们的想法(例如,插入元素、擦除对象、更改颜色等)。然后,这些交互由多模态大型语言模型(MLLM)监控,以实时预测用户意图,从而绕过了提示输入的需要。最后,我们应用了强大的扩散先验,并通过精心学习的双分支插件模块进行了增强,以精确控制的方式处理编辑请求。请访问 https://magicquill.art/demo/...