
论文阅读二十三:基于零样本知识测试的LLM幻觉推理
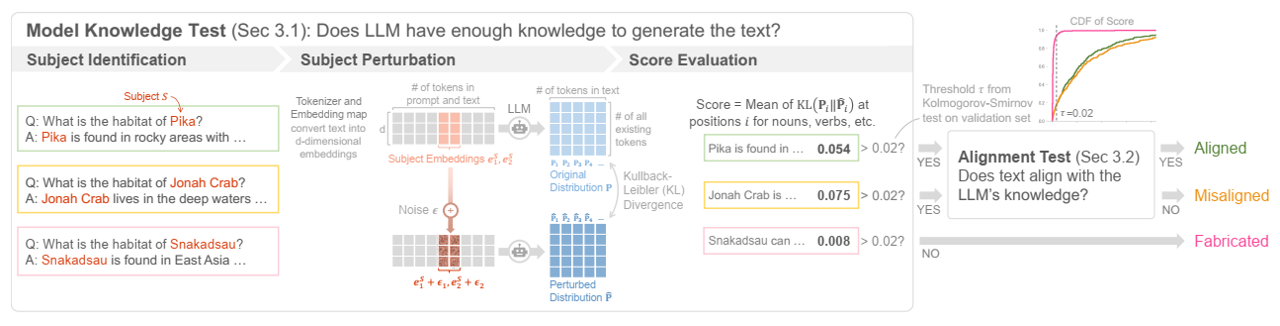
摘要 LLM幻觉,LLM偶尔会产生不忠实的文本,对其实际应用构成了重大挑战。大多数现有的检测方法依赖于外部知识、LLM微调或幻觉标记的数据集,并且它们不能区分不同类型的幻觉,而幻觉对于提高检测性能至关重要。我们引入了一个新的任务,幻觉推理,它将LLM生成的文本分为三类:对齐、未对齐和伪造。我们新颖的零样本方法评估LLM是否对给定的提示和文本有足够的知识。我们在新数据集上进行的实验证明了我们的方法在幻觉推理中的有效性,并强调了它对提高检测性能的重要性。...
论文阅读二十二:有限数据微调语言模型实用指南
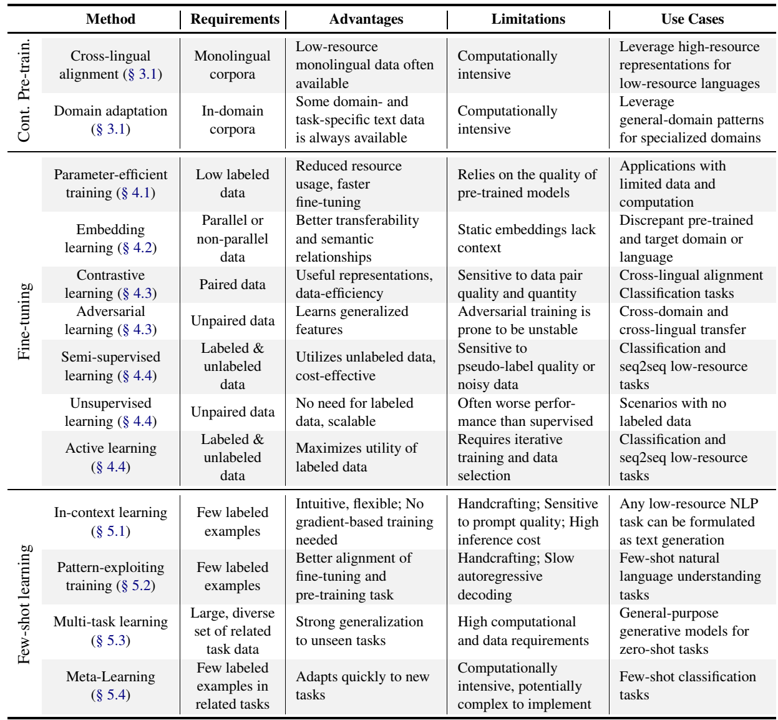
摘要 使用预训练大型语言模型(LLMs)已经称为自然语言处理(NLP)中的事实标准,尽管它们需要大量数据。受最近以有限数据训练LLM为重点的研究激增的启发,特别是在低资源领域和语言中,本文调查了最近的迁移学习方法,以优化数据稀缺的下游任务中的模型性能。我们首先解决初始化和持续的预训练策略,以更好地利用未知领域和语言的先验知识。然后,我们研究如何在微调和少样本学习过程中最大限度地利用有限的数据。最后一节从特定任务的角度,回顾了适用于不同数据稀缺程度的模型和方法。我们的目标是为从业者提供实用的指导方针,以克服数据受限带来的挑战,同时突出未来研究的有前景的方向。论文地址 引言 预训练语言模型(PLMs)正在改变NLP领域,显示出学习和建模来自复杂和多样化领域的自然语言数据底层分布的出色能力(Han等人,2021)。然而,他们的训练需要大量的数据和计算资源,这在许多现实世界场景中可能是令人望而却步的(Bai et al.,2024),尤其是对于英语以外的语言和专业领域,例如医学(Crema et al.,2023;Van Veen et al.,2021)、化学(Jablonka et...
论文阅读二十一:通过近似因子分解克服强化学习中的维数诅咒
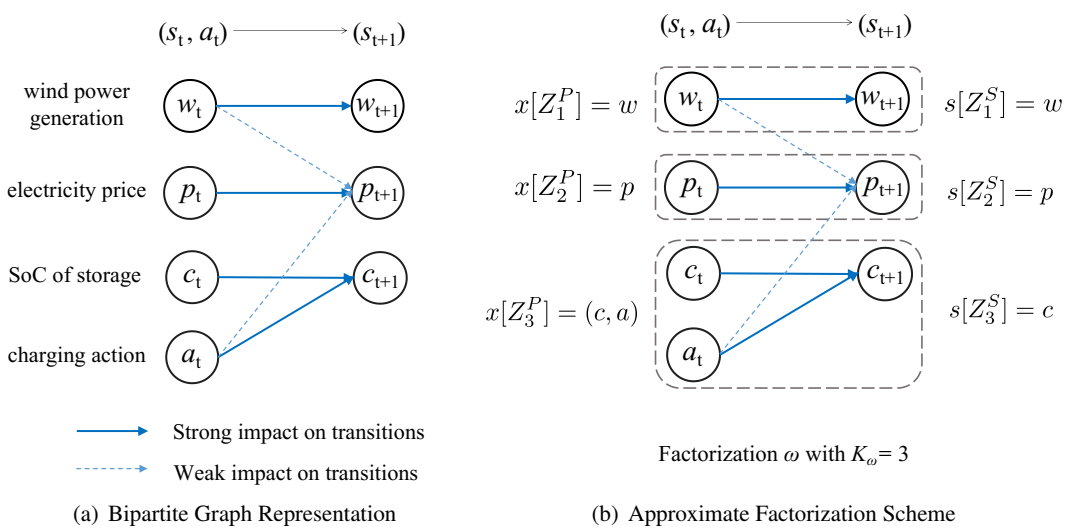
摘要 众所周知,强化学习(RL)算法存在维数灾难,这是指大规模问题往往导致样本复杂度呈指数级增长。常用解决方案是使用深度神经网络进行函数近似。然而,这种方式通常缺少理论保障。为了理论性地解决维数诅咒,我们观察到,许多真实世界问题显示出特定任务的结构,当适当利用时,可以改进RL的样本效率。基于这种见解,我们提出通过将原始马尔可夫决策过程(MDP)近似分解到较小的、独立演化的MDPs来解决维数诅咒。这种因子分解使得在基于模型和无模型的环境中开发样本高效的RL算法成为可能,后者涉及方差减少的Q学习变体。我们为这两种提出的算法提供了改进的样本复杂度保证。值得注意的是,通过MDP的近似因式分解利用模型结构,样本复杂性对状态动作空间大小的依赖性可以呈指数级降低。从数值上讲,我们通过在合成MDP任务和配备风电场的储能控制问题上的实验证明了我们提出的方法的实用性。论文地址 引言 近年来,强化学习已经成为未知环境中解决序列决策问题的流行框架,应用在不同领域,如机器人(Kober等,2013)、运输(Haydari &...
论文阅读二十:优化缩放LLM测试时间计算比缩放模型参数更有效
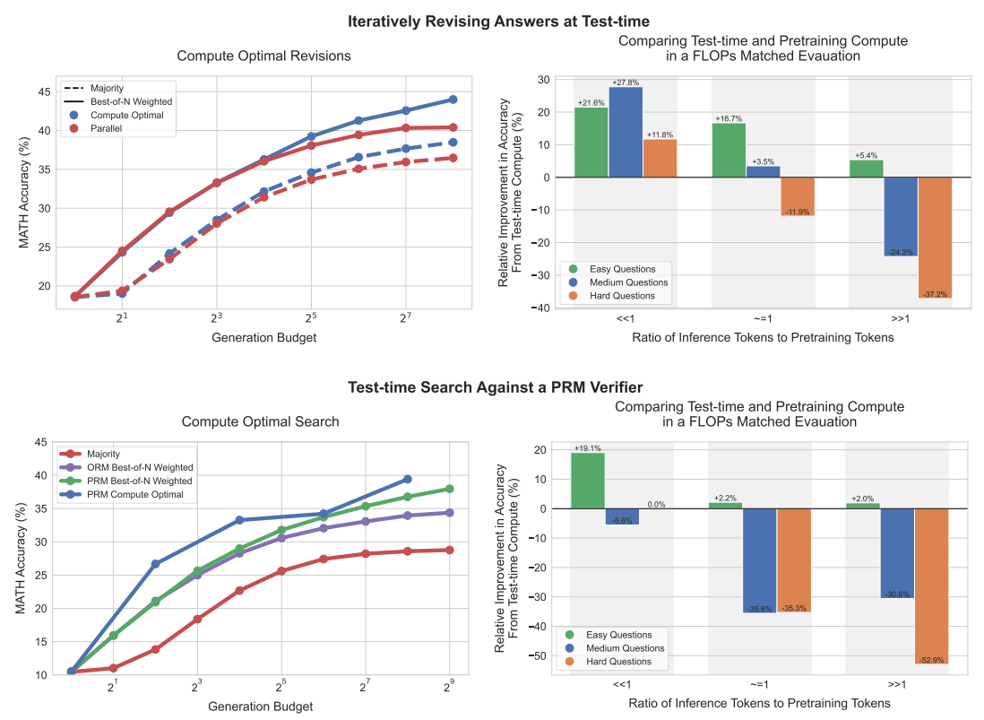
使LLM能够通过使用更多的测试时间计算来提高其输出,是构建可以在开放式自然语言上运行的一般自我改进代理的关键一步。本文研究了LLM中推理时间计算的缩放,重点回答了以下问题:如果允许LLM使用固定但非微不足道的推理时间计算,那么它在具有挑战性的提示下能提高多少性能?回答这个问题不仅对LLM的可实现性能有影响,而且对LLM预训练的未来以及如何权衡推理时间和预训练计算也有影响。尽管它很重要,但很少有研究试图了解各种测试时间推理方法的缩放行为。此外,目前的工作在很大程度上为其中一些策略提供了负面结果。在这项工作中,我们分析了两种主要的机制来扩展测试时间计算:(1)针对密集的、基于过程的验证者奖励模型进行搜索;以及(2)在测试时给出提示的情况下自适应地更新模型在响应上的分布。我们发现,在这两种情况下,缩放测试时间计算的不同方法的有效性因提示的难度而异。这一观察结果促使应用...
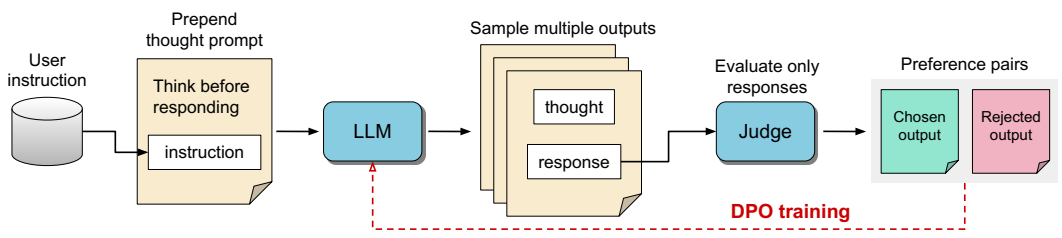
论文阅读十九:思维LLMS:思维生成的一般指导
摘要 LLM通常经过培训,能够回答用户问题或遵循指示,类似于人类专家的反应方式。然而,在标准的对齐框架内,它们缺少回答前显式思考的基本能力。思考对于需要推理和规划的复杂问题是重要的,但可以用于任意任务。我们提出了一种训练方法,在不使用额外人工数据的情况下,为现有的LLM配备这种思维能力,以便进行一般指导。我们通过迭代搜索和优化过程来实现这一点,该过程探索了可能的思维生成空间,使模型能够在没有直接监督的情况下学习如何思考。对于每一条指令,使用判断模型对候选思维进行评分,仅评估他们的反应,然后通过偏好优化进行优化。我们发现,这一程序在AlpacaEval和Arena...
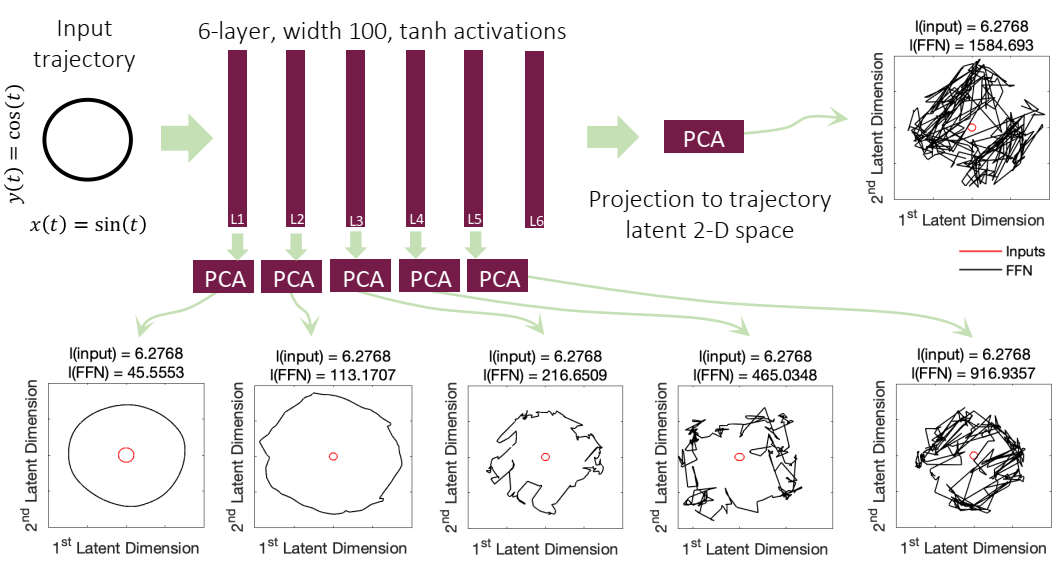
论文阅读十八:液体时间常数网络
摘要 我们介绍一类新的连续时间循环神经网络模型。我们不是通过隐式非线性来声明学习系统的动态,而是构建通过非线性互连门调制的线性一阶动态系统网络。由此产生的模型表示具有与其隐藏状态耦合的变化(即液体)时间常数的动态系统,其输出由数值微分方程求解器计算。这些神经网络展示了稳定和有界的行为,在神经常微分方程族中产生优越的表现力,提高了在时间序列预测任务上的性能。为了证明这些特性,我们首先采用理论方法来寻找它们动态性上的界限,并通过在潜在轨迹空间中测量的轨迹长度计算它们的表达能力。我们然后执行一系列时间序列预测实验来展示液体时间常数网络(LTCs)相较于经典和现代RNNs的近似能力。 引言 具有由常微分方程(ODEs)确定的连续时间隐藏状态的循环神经网络(RNN),是用于建模医药、工业和商业环境中无处不在的时间序列数据的有效算法。神经ODE的状态,x(t)∈RDx(t)\in R^Dx(t)∈RD ,由此方程的解定义: dx(t)/td=f(x(t),I(t),t,θ)dx(t)/td =...

论文阅读十六:SiT:利用可扩展的插值Transformers探索基于流和扩散的生成模型
摘要。 我们提出可扩展插值Transfomrers(SiT),这是建立在扩散Transformers(DiT) 骨干上的一类生成模型。插值框架,比标准扩散模型,允许以一种更为灵活的方式连接两个分布,使得各种影响构建在动态性传输上的生成模型设计选择的模块化研究成为可能:离散或连续时间学习、目标函数、连接分布的插值,和确定性或随机采样。通过仔细引入上述成分,SiT在条件ImageNet...

论文阅读十五:随机自回归视觉生成
摘要 这篇文章提出用于视觉生成的随机自回归模型(RAR),在图像生成任务上达到最先进的性能,同时保持与语言模型框架完全兼容。提出的RAR很简单:在具有下一个标记预测目标的标准自回归训练过程中,输入序列(通常以栅格形式排序)以概率 r 随机排列为不同的分解顺序,其中 r 从 1 开始并在训练过程中线性衰减为 0。这种退火训练策略使模型能够学习最大化所有分解顺序的预期似然,从而有效提高模型建模双向上下文的能力。重要的是,RAR保留自回归建模框架的完整性,确保与语言建模完全兼容,同时极大改善图像生成的性能。在ImageNet-256基准,RAR取得1.48的FID分数,不仅超越先前的现金自回归图像生成器,还优于领先的基于扩散和基于掩码transformer的方法。代码和模型在: https://github.com/bytedance/1d-tokenizer...
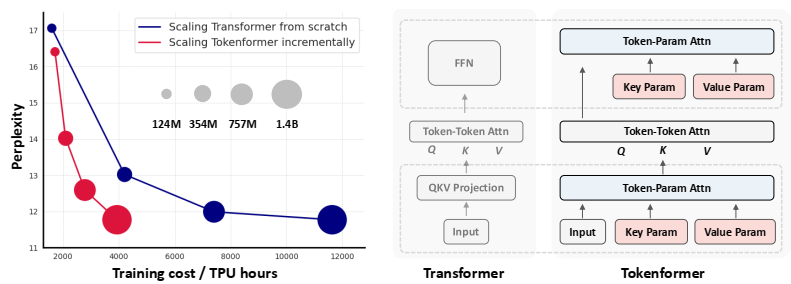
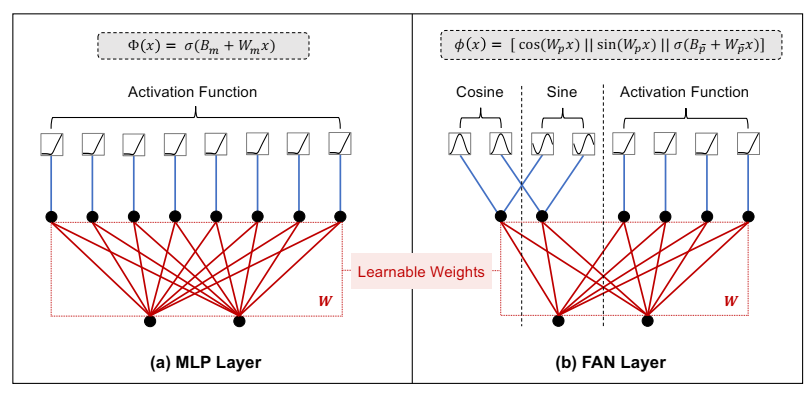
论文阅读十四:TOKENFORMER:用标记化模型参数重新思考Transformer缩放
摘要 Transformers已经成为基础模型的主导架构,由于它们在各种领域的优越性能。然而,这些模型的大量扩展成本仍然是一个值得关注的问题。这个问题主要起源于它们依赖于线性投影中的固定参数数量。当引入架构修改(如,通道维度),整个模型通常需要重新开始训练。随着模型尺寸继续增长,这种策略导致不但增长的高计算成本,从而变得不可持续。为了克服这个问题,我们引入Tokenformer,一个原生可扩展的架构,其注意力机制不仅用于输入标记之间的计算,而且用于标记和模型参数之间的交互,从而增强了架构的灵活性。通过将模型参数看待为标记,我们将Transformers中所有线性投影替换为我们的标记-参数注意力层,其中输入标记作为查询,模型参数作为键和值。这种重构允许渐进和高效扩展,而无需从头再训练。我们的模型通过增量添加新的键值参数对从124M扩展到1.4B参数,取得可比拟于从头开始训练的Transformers的性能,同时极大减少训练成本。代码和模型在:https://github.com/Haiyang-W/TokenFormer...
