
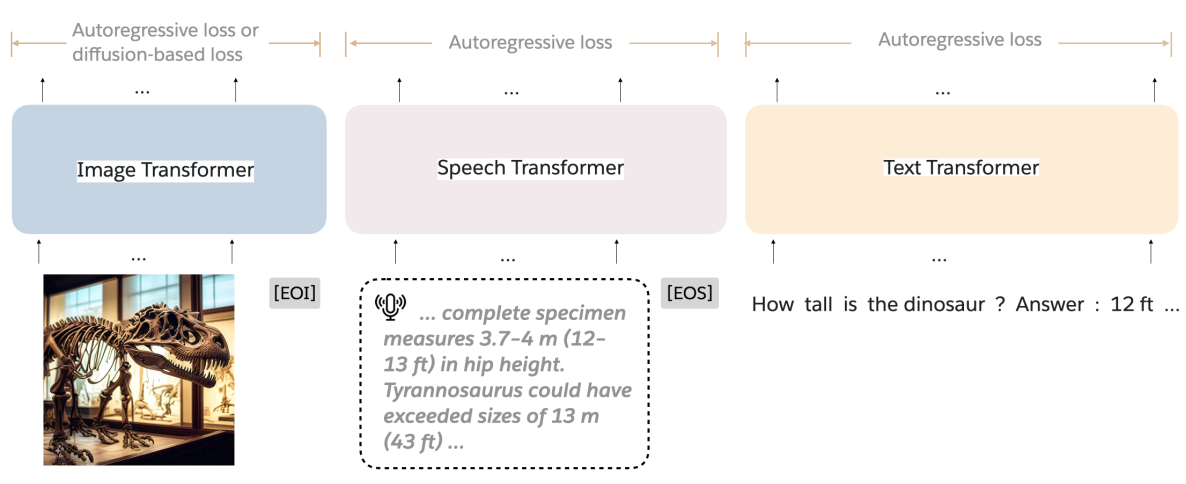
论文阅读十三:混合Transformer:一种用于多模态基础模型的稀疏可扩展架构
摘要 大型语言模型(LLMs)的发展已经扩张到多模态系统,能够在一个统一的框架内处理文本、图像和语言。相比训练仅文本的LLMs,训练这些模型需要非常大的数据集和计算资源。为克服这种扩张挑战,我们引入混合Transformer(MoT),一种稀疏多模态transformer架构,显著减少预训练计算成本。MoT通过模态解耦模型的非嵌入参数——包括前馈网络、注意力矩阵和层归一化——在整个输入序列上实现了具有全局注意力的特定模态处理。我们在多种设置和模型尺度上评估MoT。在Chameleon 7B设置上(自回归文本图像生成),MoT仅使用55.8%的FLOPs来匹配密集基准的性能。当扩展到包含语言,MoT仅使用37.2%的FLOPs达到可比拟密集基准的语音性能。在Transfusion设置中,其中文本和图像使用不同目标训练,7B MoT使用三分之一的FLOPs匹配密集基准的图像模态性能,760M...
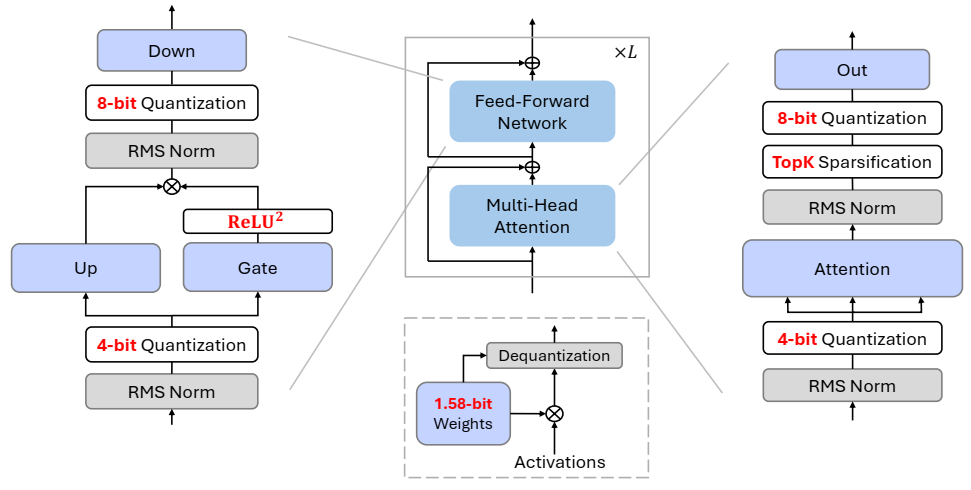
论文阅读十:BitNet a4.8:1位LLM的4位激活
摘要 最近对1位大型语言模型(LLM)的研究,如BitNet b1.58[MWM+24],为降低LLM的推理成本同时保持其性能提供了一个有前景的方向。在这项工作中,我们引入了BitNet a4.8,为1位LLM启用4位激活。BitNet a4.8采用混合量化和稀疏化策略来减轻异常信道引入的量化误差。具体来说,我们利用4位激活作为注意力和前馈网络层的输入,同时对中间状态进行稀疏化,然后进行8位量化。大量实验表明,BitNet a4.8在同等训练成本下实现了与BitNet b1.58相当的性能,同时通过启用4位(INT4/FP4)内核实现了更快的推理。此外,BitNet a4.8仅激活55%的参数,并支持3位KV缓存,进一步提高了大规模LLM部署和推理的效率。论文地址 BitNet a4.8 的概览,包括权重和激活量化。所有参数都是三元的(即 BitNet b1.58 [MWM+24] 中的 1.58 位)。我们使用混合量化和稀疏化策略来处理某些 Transformer...
文章阅读一:使用中学数学从头开始理解LLM
原文链接 本文中,我们讨论大型语言模型(LLMs)如何工作,从头开始 ———— 假设你仅知道两个数的加法和乘法。这篇文章是完全独立的。我们从用纸笔构建一个简单生成式AI开始,然后了解我们需要的一切,一边对现代LLMs和Transformer架构有一个深刻理解。本文将剔除机器学习中所有花里胡哨的东西,尽可能简单的表示一切:数字。我们仍然会在您阅读专业术语内容时,指出这些东西的名称,以束缚你的想法。 从加法/乘法到当今最先进的人工智能模型,在不假定其他知识或参考其他来源的情况下,这意味着我们涵盖了大量的内容。这不是一个玩具 LLM 解释–理论上,一个有决心的人可以从这里的所有信息中重新创建一个现代...
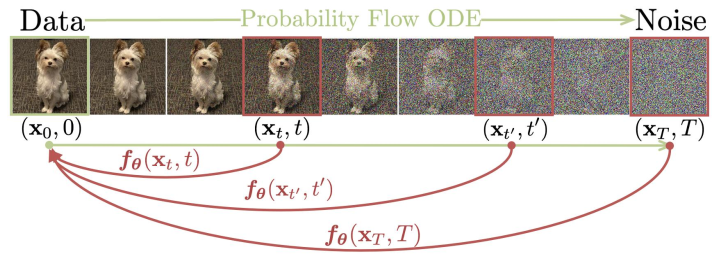
论文阅读八:一致性模型
摘要 虽然扩散模型在图像、音频和视频生成领域获得显著进展,但它们依赖于迭代采样过程,导致生成缓慢。为克服该限制,提出一致性模型。一致性模型直接映射噪声到数据,以生成高质量样本。通过设计,支持快速一步生成,同时允许多步采样,以平衡计算和采样质量。它们还支持零样本(zero-shot)数据编辑,例如图像恢复、着色和超分辨,而无需再这类任务上额外训练。一致性模型可以通过两种方式训练:(1)蒸馏预训练扩散模型,或者(2)作为独立生成模型。通过大量实验证明,它们优于现有扩散模型一步和几步采样的蒸馏技术,对于一步生成,获得CIFAR-10上3.55和ImageNet 64×6464\times6464×64 上6.20的先进FID水平。当独立训练时,一致性模型成为一个新系列的生成模型,在诸如CIFAR-10、ImageNet64x64和LSUN 256x256标准基准上,优于现有的一步、非对抗生成模型。 如下图,数据通过概率流常微分方程(PF-ODE)转为噪声。在PF-ODE轨迹上的任意点 xtx_txt...
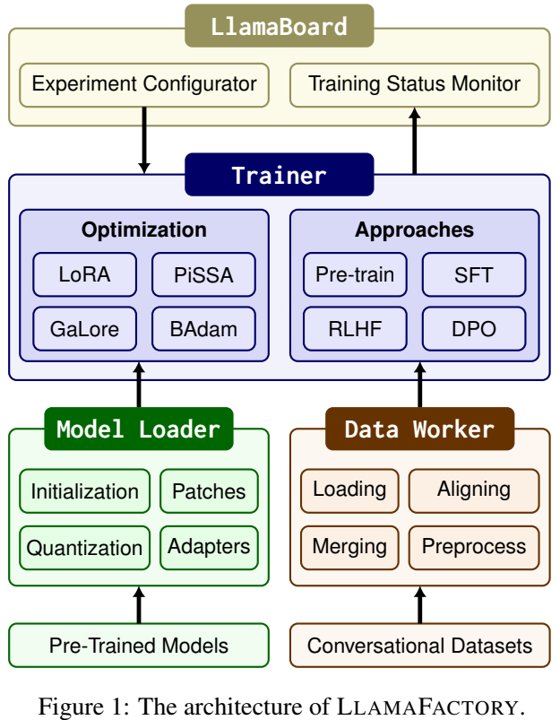
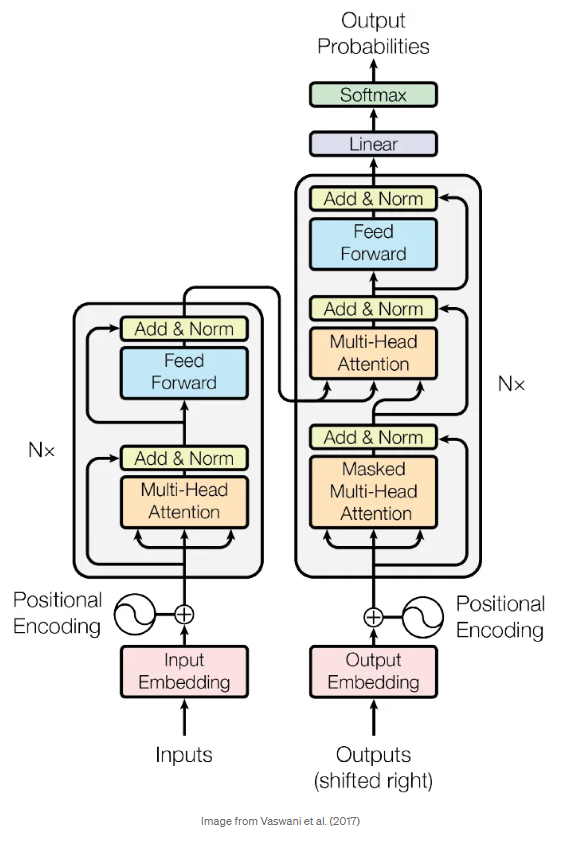
论文阅读七:LLaMA-Factory:100多种语言模型的统一高效微调
摘要 高效的微调对于使大型语言模型(LLM)适应下游任务至关重要。然而,在不同的模型上实现这些方法需要付出巨大的努力。我们介绍LLAMAFACTORY,这是一个整合了一套尖端高效训练方法的统一框架。它提供了一种解决方案,可以灵活地定制100多个LLM的微调,而无需通过内置的web UI LLAMABOARD进行编码。我们实证验证了我们的框架在语言建模和文本生成任务上的效率和有效性。它已发布于 https://github.com/hiyouga/LLaMA-Factory ,并获得了25000多颗星和3000个fork。 引言 大型语言模型(LLM)(赵等人,2023)具有显著的推理能力,并赋予了广泛的应用,如问答(Jiang等人,2023b)、机器翻译(Wang等人,2023c;Jiao等人,2023a)和信息提取(Jiao等人(2023b))。随后,大量LLM被开发出来,并可通过开源社区访问。例如,Hugging...
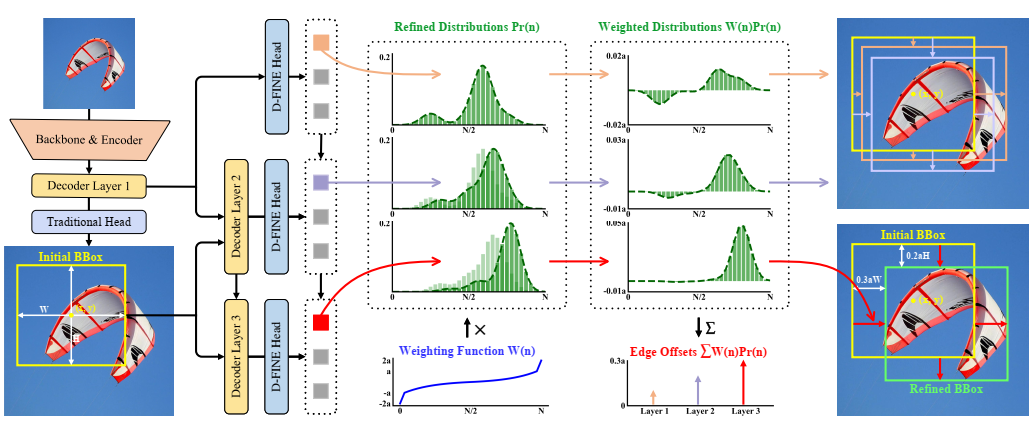
论文阅读五:D-FINE:将DETRS中的回归任务重新定义为细粒度分布细化
摘要 我们介绍了D-FINE,这是一种强大的实时对象检测器,通过在DETR模型中重新定义边界框回归任务,实现了出色的定位精度。D-FINE包括两个关键组成部分:细粒度分布细化(FDR)和全局最优定位自蒸馏(GO-LSD)。FDR将回归过程从预测固定坐标转换为迭代细化概率分布,提供了一种细粒度的中间表示,显著提高了定位精度。GOLSD是一种双向优化策略,通过自蒸馏将定位知识从精细分布转移到较浅层,同时简化了较深层的残差预测任务。此外,D-FINE在计算密集型模块和操作中采用了轻量级优化,在速度和精度之间实现了更好的平衡。具体来说,D-FINE-L/X在NVIDIA T4 GPU上以124/78 FPS的速度在COCO数据集上实现了54.0%/55.8%的AP。在Objects365上进行预训练时,D-FINE-L/X的AP达到57.1%/59.3%,超过了所有现有的实时检测器。此外,我们的方法显著提高了各种DETR模型的性能,AP高达5.3%,额外参数和训练成本可以忽略不计。我们的代码和预训练模型:https://github.com/Peterande/D-FINE...
